



The F–16 is still an incredible piece of technology, with many innovations that protect it from enemies and make it an efficient multirole aircraft. However, even the most advanced technology can be rendered useless by something as simple as a forgotten screwdriver. In a 9-g environment and at Mach 2 speed, this innocent tool can be more dangerous than even a sophisticated anti-aircraft missile. F–16 ground crews know that any shift in operational processes can result in the grounding of the F–16, no matter how advanced and innovative it is.
Network Operations Teams
Network operations teams are also under pressure to adhere to a different strict policy – a “five nines” (99.999%) service-level agreement (SLA). They are aware that even a brief amount of downtime can lead to lost revenue, damaged reputation, legal liability, and brand dilution from a business perspective. Therefore, network operations teams prioritize smooth operations before exploring the potential benefits of new technologies and innovations.
For both F-16 crews and network operations teams, technological advancement is only attainable through operational excellence.
Network Operations Challenges and Concerns
Despite thin margins, service providers continue to invest in their infrastructure to meet the unstoppable demand for network traffic. Service providers are therefore looking for innovative solutions to handle increased network traffic, while keeping costs low. However, promised cost savings, agility and scalability are not enough on their own. Networking vendors, particularly those that offer a radical network change in the form of a distributed disaggregated chassis (DDC), must evaluate their solution from the perspective of the operations team, taking into account their main challenges and concerns.
Network Availability and Performance
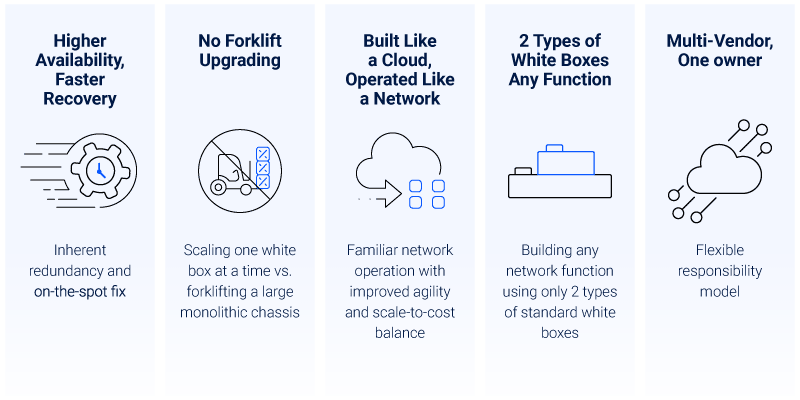
Network outages can be devastating to the service providers’ business, leading to lost revenue, increased churn, and a decline in net promoter score (NPS). As a result, operations teams will do everything possible to prevent network outages. If one does occur, teams will aim to minimize the blast radius and speed up recovery in order to minimize the negative impact. They will do this by seeking a solution that can leverage distributed and disaggregated architecture, which allows the separation of every function or component in order to minimize the blast radius. This way, a failure in one service/component will not affect the operation of the rest of the shared infrastructure, and the network cluster can continue to operate seamlessly. Furthermore, in case of a failed component, a disaggregated solution can also provide a fast replacement without affecting network availability
Network Management and Integration
There are legitimate concerns from network operations teams regarding new technologies, especially ones with unfamiliar operational processes. After all, any change or inconsistencies in integration with other vendors can negatively impact network availability, which is their main key performance indicator (KPI). To avoid this, operations teams should push for cloud-native architectures that allow them to run network functions (e.g. routers) in containers, while the underlying hardware is one orchestrated shared resource. This way, any network function can be operated independently, leaving network operators with familiar and seamless operations on top of the technological and business promises.
Network Complexity
It’s common to use 5-20 types of routing boxes in a network, as different network domains often require different routing solutions. This doesn’t even include firewalls, distributed denial-of-service (DDOS) scrubbers, monitoring tools, and load balancers. Managing and operating a network with so many “boxes” that require different management skills, software updates and spare parts can be challenging. The addition of a limited and inflexible scaling mechanism further complicates matters, making it clear why service providers seek solutions that can reduce the number of components and software environments in their networks. Service providers should choose a solution that can also deploy the same “reduced” components across any network domain and meet any performance or capacity requirements with simple and flexible scaling capabilities.
Responsibility and Concerns for Multi-vendor Network Solutions
Service providers and their operations teams would love to be free of vendor lock-in, but a multi-vendor solution may lead to finger-pointing between vendors during a root-cause analysis. When vendors start blaming each other, it can be extremely difficult to resolve the issue at hand. To avoid this, service providers should strive for a multi-vendor solution that offers a flexible responsibility model. This way, the service provider can choose a leading vendor to take complete end-to-end responsibility for the solution and, if desired, shift to a shared responsibility model where the service provider takes the lead on hardware or software issues.
Network Cloud – Better for Operations
DriveNets Network Cloud has already been deployed by many tier-1 service providers, and more SPs are expected to deploy Network Cloud in the near future. We believe that our strong growth is in part due to our understanding that operations teams play a crucial role in the success of new solution implementations. As a result, DriveNets Network Cloud not only delivers cost savings, agility, and scalability, but also significantly improves the operational experience for service providers.
The following are the five key benefits that drive the superior network operations of DriveNets Network Cloud:
Download eBook
Network Cloud, Better Operations