CloudNets Video
What's the importance of latency in AI networks. AI networks introduce new challenges that need different treatments of latency....
Read more

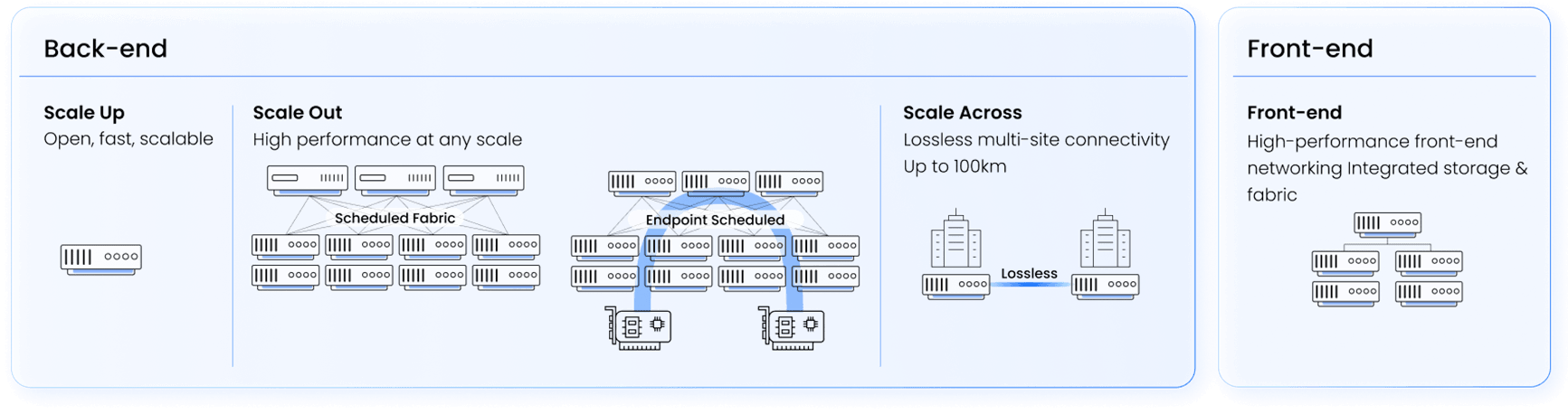
DriveNets AI Fabric portfolio provides Ethernet-based, high-performance open networking solutions supporting multiple AI networking use cases:
All solutions provide:

NeoCloud/GPUaaS infrastructure, either purpose built or reassigned from crypto-mining, requires exceptional scalability, flexibility, multi-site and multi-tenant support to accommodate diverse cloud-native AI workloads. DriveNets AI Fabric delivers these capabilities through its innovative fabric-scheduled or endpoint scheduled architectures — optimized for AI-driven environments. With the ability to host multiple tenants without fine-tuning, ensure resource isolation between tenants – avoiding the noisy neighbor effect, and supporting remote, multi-site deployments, it simplifies operations while providing consistent performance. DriveNets empowers NeoCloud providers to scale effortlessly and innovate without the limitations of traditional network infrastructures.
AI hyperscaler networks demand unparalleled scalability, performance, and simplicity to support the needs of very-large-scale GPU clusters. DriveNets AI Fabric rises to this challenge with a software-driven architecture that supports extremely large GPU cluster sizes, leveraging Ethernet technology to ensure seamless integration and operation. Unlike traditional solutions, DriveNets eliminates the need for specialized knowledge from technical staff, simplifying deployment and management. It’s easy-to-scale, distributed, disaggregated design enables hyperscalers to expand capacity effortlessly while maintaining optimal performance and efficiency—empowering innovation without the limitations of proprietary or complex networking systems.
Best performance solution for Hyperscalers AI-fabric
AI enterprise backend networks demand exceptional performance and scalability to support the growing reliance on AI-driven workloads and data-intensive applications. DriveNets AI Fabric addresses these needs with a distributed, scheduled fabric architecture—scalable, cost-effective, and optimized for AI workloads that fits all Enterprise use cases including financial research, life science and pharmaceutical research, automotive, energy & utilities and high education. Its Fabric Scheduled Ethernet and Endpoint Scheduled Ethernet technologies enable enterprises to seamlessly adapt to evolving AI demands, ensuring high performance, no vendor lock, operational simplicity, and the ability to innovate without the constraints of proprietary network designs.

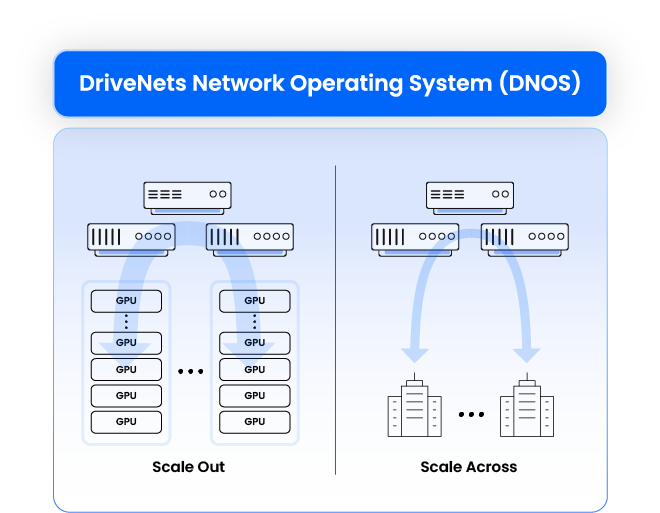
Backend networking in AI clusters refers to the interconnect infrastructure that facilitates internal communication between AI accelerators (such as GPUs) within a data center (scale-out) or between datacentes (scale-across). This is a critical piece of the AI cluster infrastructure as it accommodates the sensitive traffic enabling efficient parallel processing and data sharing.
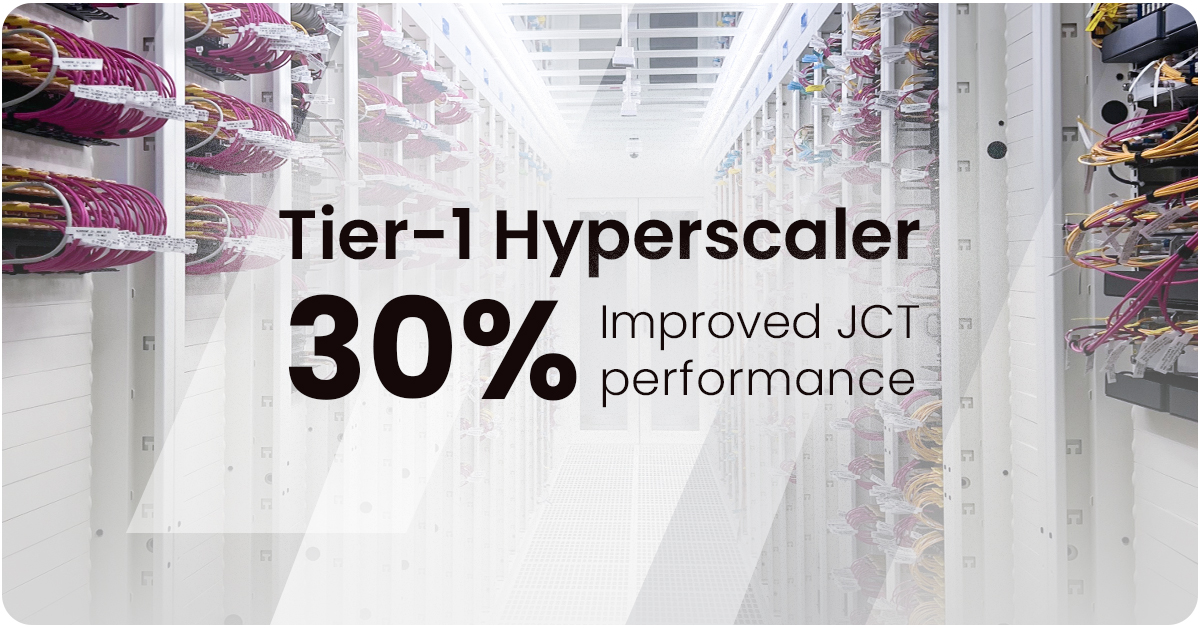
DriveNets AI Fabric transforms scale-out and scale-across networking by combining the flexibility of Ethernet with the high-performance characteristics required for AI workloads. Unlike traditional Ethernet solutions, DriveNets AI Fabric leverages scheduled Ethernet technologies, advanced architectures that ensures lossless and predictable network performance while optimizing load balancing and latency. By eliminating packet loss and minimizing GPU idle time, DriveNets AI Fabric optimizes job completion time (JCT)—outperforming both standard Ethernet and proprietary InfiniBand technologies. This next-generation approach enables seamless scalability, cost efficiency, and superior AI workload acceleration, making it the ideal choice for AI-driven data centers.
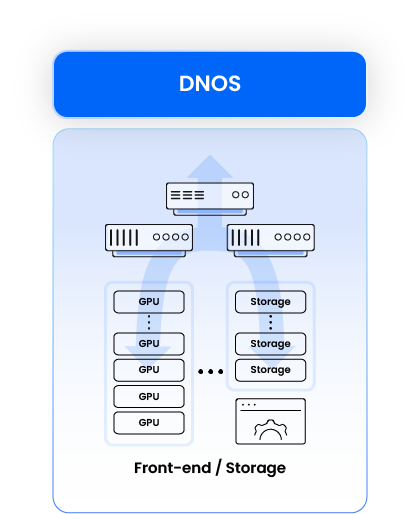
Frontend networking in AI/HPC clusters refers to the network infrastructure that manages external data traffic between AI workloads and users, applications, or other services. It connects the AI cluster to the broader data center, cloud services, or enterprise systems. Frontend networking must provide high bandwidth, low latency, and secure connectivity to ensure seamless interaction between AI models and end-users or business applications.
Storage networking in AI clusters is responsible for handling the massive data transfer between the AI compute nodes and external storage systems. For AI workload, unlike typical HPC implementations, this is a critical infrastructure as this traffic is intense and insufficient performance of the storage fabric will result in poor overall workload performance.
DriveNets AI Fabric provides a unified solution for both networking fabrics, sharing the same Ethernet-based technology, architecture and actual implementation with the back-end fabric.

What happens when you use AI to explain AI?
We used NotebookLM to turn our technical concepts into quick, 60-second deep dives.
Check out the series and explore AI networking concepts, from high-speed fabrics to low-latency clusters.
CloudNets Video
What's the importance of latency in AI networks. AI networks introduce new challenges that need different treatments of latency....
Read moreBlog
If it were up to my twins, they would spend all their waking hours on their smartphones. That’s why I...
Read moreBlog
In today’s competitive artificial intelligence (AI) landscape, hyperscalers and large enterprises are rapidly recognizing the critical need for open, scalable,...
Read more