



|
Getting your Trinity Audio player ready...
|
This was the focus of a recent joint webinar, “Build It Right: AI Cluster End-to-End Performance Tuning,” hosted by DriveNets and Semper Victus.
During the session, Toby Ford (Chief Network Architect, Semper Victus) and Sagi Fenish (Senior Director, AI Infrastructure, DriveNets) shared the step-by-step journey of designing, deploying, and optimizing a large-scale AI cluster built for White Fiber in Iceland.
What were the customer requirements?
At the heart of the project were the ambitious requirements defined by WhiteFiber.
- WhiteFiber wanted a unified fabric capable of handling storage, compute, and edge connectivity on the same network—eliminating the complexity of running multiple parallel fabrics.
- WhiteFiber needed to reduce network congestion, a common pain point when exposed to demanding AI workloads.
- Deployment speed was critical: the cluster had to achieve fast time-to-performance with minimal fine-tuning, ensuring optimal job completion time (JCT).
- The solution had to deliver high performance at scale, supporting a 512-GPU cluster at maximum efficiency.
- WhiteFiber insisted on a standards-based Ethernet approach, retaining the operational flexibility, ecosystem compatibility, and simplicity of Ethernet while still achieving InfiniBand-class performance.
Designing a Unified Fabric
Traditional GPU clusters often rely on multiple fabrics—separate networks for compute, storage, and front-end traffic. DriveNets and Semper Victus chose a different path: a converged fabric.
The design used a single-leaf TOR architecture rather than a traditional 8-rail approach, allowing for larger scalability without exponential cabling complexity. The challenge, however, was ensuring that this architecture could still deliver low tail latency, full bisection bandwidth, and resilience under heavy AI traffic patterns (elephant flows with low entropy).
DriveNets’ solution: a fabric-scheduled Ethernet. Instead of relying on hash-based load balancing, the system breaks packets into cells (“cell spray”), distributes them evenly across all available links, and ensures lossless delivery with ingress/egress credit scheduling. This guarantees 100% utilization without congestion collapse, eliminating common Ethernet pitfalls like head-of-line blocking.
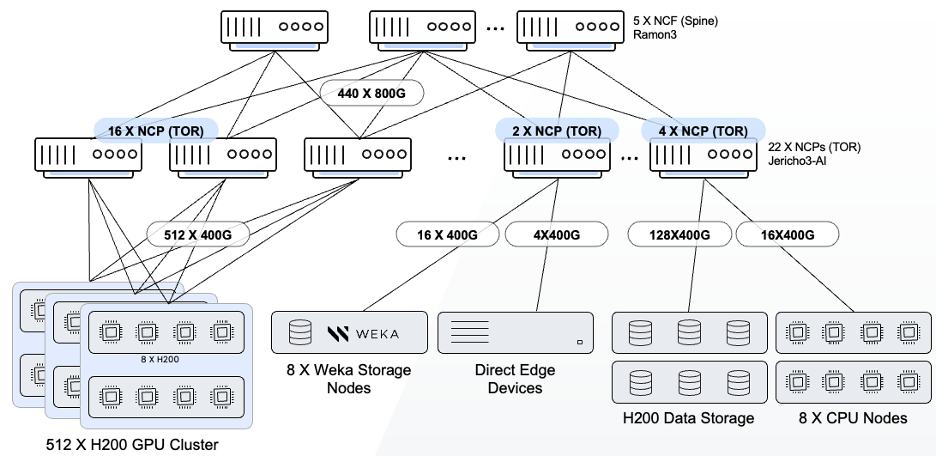
Diagram 1: Network design – the chosen architecture
Basically, what you see in diagram 1 is the network design, there was a request to bring something new to the table—to build a unified or converged fabric that consolidates backend compute, backend storage, and front-end connectivity over the same fabric. This, of course, introduces challenges: on the one hand, you want everything unified, but on the other, you cannot afford any performance degradation. The expectation is that every workload—whether storage traffic or GPU-to-GPU communication—should be isolated, achieve full performance and reach its full potential. This is exactly what we deliver with the solution proposed here: a fabric-scheduled Ethernet architecture from DriveNets. It provides a fully end-to-end scheduled Ethernet fabric, operating leaf-to-leaf in a congestion-free manner, using VOQs for trafic isolation, ensuring full fabric utilization and ultimately delivering the highest-performing Ethernet available today.
Managing Cabling and Topology
If there was a “hidden hero” in this project, it was cable management. A 64-node GPU cluster with unified fabric involves thousands of fiber connections. Poor labeling or sloppy organization can make debugging nearly impossible.
To avoid chaos, Semper Victus relied on NetBox automation for:
- Generating bills of materials (BOM)
- Auto-labeling cables and ports
- Printing labels directly for deployment
This ensured that any future debugging or remediation could be done cleanly, DriveNets’ Infrastructure Services (DIS) team handled the rack, stack, and cabling, applying proven best practices to keep the system maintainable.
Server & NUMA Optimization
The HPE Cray XD670 nodes introduced another layer of complexity: NUMA topology.
- Each server is divided into NUMA nodes that bind CPUs, NICs, memory, and I/O resources.
- If left misconfigured, NUMA can cause severe performance degradation, especially in GPU-to-GPU communication.
- Through testing, the team discovered that sub-NUMA clustering had to be disabled to achieve optimal results.
- They iterated across multiple BIOS settings and configurations, comparing against competitors’ systems, until they found the sweet spot that unlocked consistent performance.
Provisioning & Firmware Discipline
With the physical build complete, the team turned to software and firmware. Using Canonical MAAS, they automated initial provisioning—testing CPU, memory, and disks before installing Ubuntu 22.04, CUDA, and NVIDIA drivers.
What was one key lesson?
In any large-scale deployment, a fraction of nodes will fail (either initially or during burn-in). Firmware mismatches, NIC driver issues, and hardware seating problems can cripple performance. The team emphasized firmware uniformity and proactive remediation—reseating cards, cleaning fiber edges, and replacing defective units when needed.
Network & NIC Tuning
AI fabrics demand fine-grained tuning beyond defaults. Out-of-the-box NIC settings are unsuitable for AI workloads.
The team reconfigured NICs to:
- Enable PFC and ECN
- Move from PCP trust mode to DSCP trust mode
- Adjust buffer sizes and congestion settings
- Ensure persistence with systemd scripts and MLX config tools
They also emphasized the importance of avoiding aggressive congestion control values. Thanks to DriveNets’ scheduled Ethernet, the system performed equally well with or without congestion control, something traditional Ethernet switches cannot achieve.
Validation & Layer 1 Integrity
Before running AI workloads, the team validated topology discovery—ensuring actual connections matched expected design. DriveNets switches provided automatic link discovery and bandwidth validation, detecting asymmetries and dynamically adjusting spray ratios.
Equally critical was fiber health monitoring. Using microscopes and cleaning tools, the team inspected connectors, proactively cleaning or replacing fibers before errors could propagate.
Benchmarking
With the cluster stable, the team turned to NVIDIA NCCL tests—the industry standard for GPU-to-GPU communication. They ran AllReduce, AllGather, ReduceScatter, and All-to-All tests, cycling each five times for statistical reliability.
This phase revealed bottlenecks that required:
- Adjusting MPI run binding strategies
- Fixing NUMA binding mismatches
- Tuning NIC parameters and U-limits
- Disabling ACS in BIOS for direct GPU-to-GPU communication
By systematically eliminating bottlenecks, we avoided misleading “good enough” results and instead achieved world-class performance metrics.
Results: How this deployment beat InfiniBand
The outcome was compelling. Compared against public benchmarks from SemiAnalysis:
- 72% better performance vs. traditional Ethernet
- 15% better than NVIDIA Spectrum-X Ethernet
- 6% better than InfiniBand on AllReduce
- Up to 28% better than InfiniBand on AllGather and ReduceScatter
These results are especially significant because modern AI models (like Mixture-of-Experts LLMs) rely heavily on AllGather and All-to-All collectives. Outperforming InfiniBand in these tests demonstrates Ethernet’s viability as the fabric of choice for next-generation AI.
What were the lessons learned?
The project highlighted several universal lessons for anyone building large-scale AI infrastructure:
- Plan for scale from the start: Simplify cabling and design to allow future growth.
- Treat cabling as mission-critical: Orderly, labeled connections save weeks of troubleshooting.
- Know your NUMA topology: BIOS settings and CPU–GPU bindings can make or break performance.
- Automate provisioning and validation: Firmware and OS consistency are essential.
- Tune for AI workloads, not defaults: NICs, buffers, and congestion control must be adapted.
- Validate with rigor: Repeat tests, apply statistical discipline, and never trust a single run.
- Ethernet can outperform InfiniBand—with the right architecture, AI clusters can achieve both performance and operational simplicity.
The WhiteFiber deployment proved Ethernet has entered a new era
With fabric scheduling, rigorous deployment practices, and disciplined optimization, it is now possible to deliver better-than-InfiniBand performance in AI clusters—without abandoning the simplicity and flexibility of Ethernet.
The key takeaway: achieving optimal results in AI infrastructure isn’t about any single component. It’s about the process—from design and cabling, through provisioning and tuning, to validation and benchmarking. With the right process, the payoff is extraordinary: an AI fabric that scales effortlessly, performs optimally, and empowers the future of AI innovation.
Frequently Asked Questions
How did the project achieve better performance than InfiniBand?
Compared against public benchmarks from SemiAnalysis:
- 72% better performance vs. traditional Ethernet
- 15% better than NVIDIA Spectrum-X Ethernet
- 6% better than InfiniBand on AllReduce
- Up to 28% better than InfiniBand on AllGather and ReduceScatter
These results are especially significant because modern AI models (like Mixture-of-Experts LLMs) rely heavily on AllGather and All-to-All collectives. Outperforming InfiniBand in these tests demonstrates Ethernet’s viability as the fabric of choice for next-generation AI
What were the customer’s main requirements for the AI cluster?
At the heart of the project were the ambitious requirements defined by White Fiber:
- A standards-based Ethernet approach—retaining operational flexibility, ecosystem compatibility, and simplicity—while still achieving InfiniBand-class performance.
- A unified fabric capable of handling storage, compute, and edge connectivity on the same network.
- Reduced network congestion when exposed to demanding AI workloads.
- Fast time-to-performance with minimal fine-tuning, ensuring optimal job completion time (JCT).
- High performance at scale, supporting a 512-GPU cluster at maximum efficiency.
What role did cabling and topology management play in the success of the project?
A 64-node GPU cluster with unified fabric involves thousands of fiber connections. Poor labeling or sloppy organization can make debugging nearly impossible.
To avoid chaos, Semper Victus relied on NetBox automation for:
- Generating bills of materials (BOM)
- Auto-labeling cables and ports
- Printing labels directly for deployment
This ensured that any future debugging or remediation could be done cleanly. DriveNets’ Infrastructure Services (DIS) team handled the rack, stack, and cabling, applying proven best practices to keep the system maintainable.
Key Takeaways
- Unified Fabric Design – A single converged fabric was built to handle compute, storage, and front-end connectivity without sacrificing performance
- Fabric-Scheduled Ethernet – DriveNets’ packet “cell spray” and ingress/egress credit scheduling eliminated congestion and delivered full utilization, achieving InfiniBand-class performance
- Cabling as a Critical Factor – Automation with NetBox for labeling and BOM generation kept thousands of fiber connections organized and maintainable
- NUMA Optimization – Disabling sub-NUMA clustering and fine-tuning BIOS settings was key to unlocking consistent server performance
- Rigorous Benchmarking – Systematic NCCL testing (AllReduce, AllGather, ReduceScatter, All-to-All) identified and removed bottlenecks, preventing misleading “good enough” results
- Ethernet Outperformed InfiniBand – The deployment achieved up to 28% better performance than InfiniBand in critical collective operations, proving Ethernet’s viability for large-scale AI workloads.
Related content for AI networking infrastructure
DriveNets AI Networking Solution
Latest Resources on AI Networking: Videos, White Papers, etc
Recent AI Networking blog posts from DriveNets AI networking infrastructure experts
Webinar
Build It Right: AI Cluster End-to-End Performance Tuning