HomeBlogLearn About Disaggregated Network’s High Availability from your Beagle
Learn About Disaggregated Network’s High Availability from your Beagle
If you’ve ever owned a beagle, you know how difficult it is to keep it healthy and alive 24/7. Beagles are typically intelligent, curious, stubborn creatures. They are insatiable, and therefore they can eat literally to death. My beagle often runs away to explore the world, sometimes crossing six lanes of traffic on a busy Friday morning, following an imaginary scent, a phantom cat, or just for fun. She once jumped off a 20m cliff for no reason at all and miraculously survived. So the very traits that define beagles and make them so appealing to many are the ones that might cause them the most harm.
Like the beagle, the disaggregated router has many traits that make it extremely appealing to Service Providers:
It breaks the vendor lock by disaggregating the software from the hardware
It separates the control and data planes so you can scale the control independently from the data plane
It lowers costs by using white boxes
It increases revenue by enabling the fast rollout of services
Service Provider Networks Must Ensure Uninterrupted Operations
Service Providers demand uninterrupted operation of their network, especially at the core, where it is most critical, where service provider software updates can’t disrupt traffic. This is their bread and butter. They could pay heavy penalties for even a short downtime that may affect millions of users and could even potentially be life-threatening. Imagine if your car manufacturer had to refund you every time your car broke down. Think about it. Your car could be out of service for days before being fixed. So why not? It would force car manufacturers to make more robust cars. But if nothing else, it would undoubtedly make your trips to the garage much less annoying.
Service Providers have very high-performance standards: five-nines. This means that a network device must have 99.999 percent availability. In other words, they only tolerate up to 5 minutes and 15 seconds of downtime in a year.
Network System Components May Fail
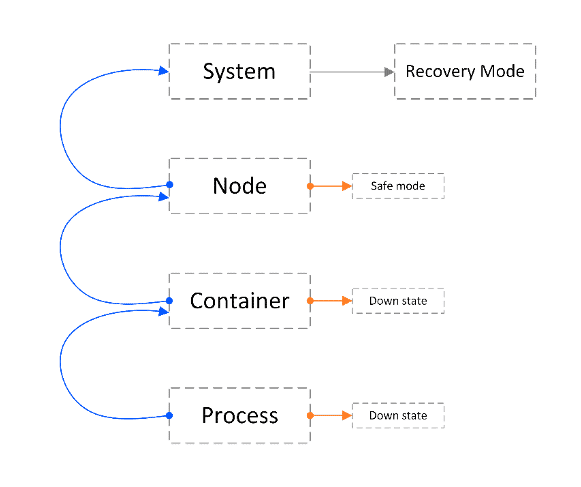
But system components may fail in multiple ways: software bugs, hardware malfunctions, power outages, etc., all conspiring to disrupt the system’s operation. This is true for any system, but the more complex the system is, the more susceptible it is to failure. As a carrier-grade networking system, our disaggregated Network Cloud solution must assure the operational performance required by Service Providers. In our solution, a single large cluster can contain dozens of boxes. On top of the hardware infrastructure, we install our cloud-native network operating system (DNOS) that makes all these boxes act as a single routing device. This robust solution architecture guarantees the device’s uninterrupted operation on all levels:
On the hardware level, it includes built-in redundancies for all cluster elements (NCP, NCF, NCC, and NCM – see our site for more info on Network Cloud architecture) so that if one component fails, the cluster can continue to operate seamlessly. Also worth mentioning, DriveNets certifies all ODM equipment to ensure that it is up to our standards.
On the software level, our cloud-native container-based architecture runs every function on a dedicated container. For example, in the control plane (NCC), all management processes run within a separate container from the routing processes. This process > container > element hierarchy can be replicated for multiple services (microservices). Not only does this allow to easily add new network services and external third-party services into the control plane, but it also isolates each microservice, so that a failure in one does not affect the operation of other microservices on the shared infrastructure.
Network Health Check Mechanisms
DNOS includes built-in health check mechanisms for monitoring processes, containers and also system resources, so that a microservice can recover quickly and seamlessly. The self-healing mechanism monitors every software element. When a software failure is detected, for example, if a process fails, the failed element is restarted based on a predefined policy. This is a fully automated policy that defines the remedy for every single software failure. It defines, for example, whether a failed element will be restarted normally, or gracefully, and if the restart will be warm or cold. It defines how many times each element can be restarted before it is shut down permanently, and whether or not to escalate the mitigation to a higher level element if the problem persists. Moreover, the policy defines the conditions for failover to the standby NCC if the active NCC fails, what to do if both NCCs fail, and many other things.
On the application level, DNOS has many features for fast link failure detection for the full routing stack spectrum, fast reroute, and LSP protection, in case a route or tunnel fails, and also protocol stack non-stop routing (NSR).
We did everything possible to avoid any single-point-of-failure and to teach the system to heal itself so that you don’t need to.
Ensure High Availability
As for me, I can see how I have implemented the same principles to ensure my dog’s high availability:
Robust architecture – I have built 1.8m walls all around my property
Redundancy – I’ve installed double doors and double gates to isolate sections of the house and garden so that if she manages to escape through one door or gate, she would still be trapped by the other door or gate.
Policy – I have had to implement new rules for disaster prevention – for example, never leave food lying around, never open the outer gate before checking where the dog is… you get the picture.
Application – I have been training my dog for most of her life to reconfigure some unwanted behaviors. Although this helps a lot, her trainer insists that we will never be able to shake the beagle out of her.
Despite all the precautions, now and then, a failure occurs that I cannot fix. For these occasions, I have the vet on speed dial. Similarly, you can contact customer support. But this is where the analogy ends. While you can have an entire system on standby ready to be used in case of a system-wide failure, no dog could ever replace this beagle.