



|
Getting your Trinity Audio player ready...
|
As AI clusters grow to thousands or even hundreds of thousands of GPUs, the network often becomes the primary bottleneck. AI cluster builders know that they might spend 90% of their budget on the fastest GPUs. But if their network is not perfectly coordinated, those expensive GPUs sit idle, waiting for data to arrive. This reduced GPU utilization increases job completion time (JCT) and cost per million tokens (CPMT), or in simpler terms, burns money.
As a result, the network often becomes a key focus area in deployment and ongoing operations for AI cluster builders.
Not including Fabric-Scheduled Ethernet (much more on that below), there are three main solutions used in the AI infrastructure industry to interconnect large-scale GPU clusters:
- InfiniBand: While InfiniBand is widely regarded as the industry benchmark for performance, it locks customers into a specific vendor (Nvidia) for their entire AI stack: networking, optics, NICs, and GPUs.
- Traditional Ethernet: This technology is mainly used in data center frontend workloads. While scalable and open, traditional Ethernet cannot meet the performance demands of large-scale AI workloads due to its lack of lossless transport, unpredictable latency, and insufficient congestion control.
- Spectrum-X: This proprietary, Ethernet-based solution from Nvida is positioned to replace InfiniBand. Spectrum-X aims to address Ethernet’s limitations through mechanisms like packet spraying and smart NICs for more efficient traffic management. However, it still cannot match InfiniBand’s low latency or lossless performance.
Validating high-performance Ethernet at scale
In this blog post, we share real-world production performance results of DriveNets AI Fabric solution and its Fabric-Scheduled Ethernet (FSE) architecture to validate its high-performance capabilities at large scale. The evaluation was based on known simulations and benchmarks using the Nvidia Collective Communications Library (NCCL), the de facto standard for AI and HPC (high-performance computing) performance testing.
The test was conducted on 512-GPU cluster in production at a DriveNets customer. To put DriveNets’ FSE performance into context, the test results were compared against public benchmarks published by SemiAnalysis (Dec 2024). This provides an external reference point for validating DriveNets’ industry-leading capabilities against leading AI/HPC cluster solutions.
What makes Fabric Scheduled Ethernet perfect for large-scale AI clusters?
Before reviewing the test results, it’s important to note that DriveNets scheduled fabric takes a different approach. Instead of the “best effort” delivery model of traditional Ethernet, it uses a highly coordinated, scheduled architecture. DriveNets’ Fabric Scheduled Ethernet architecture is built on open standards defined by the Open Compute Project (OCP). It uses standard white-box switches in a Clos topology, efficiently scheduling and managing data flow to optimize network paths, eliminate congestion, and minimize latency and jitter. The result is a highly predictable, lossless network.
Three key features drive this AI-grade performance:
- Cell-based fabric: Instead of sending a whole packet down one path, the architecture breaks data into smaller “cells” and sprays them across all fabric ports simultaneously. This “cell spray” ensures perfect load balancing while remaining fully transparent to standard Ethernet protocols.
- End-to-end virtual output queues (VOQs): This receiver-based scheduling is responsible for sending data only when the receiver is ready, delivering consistent and predictable performance regardless of traffic patterns.
- Zero-impact failover: Link health is monitored in hardware. When failures occur, traffic is re-steered automatically across remaining links within microseconds, without disrupting training jobs. This allows large GPU clusters to continue operating smoothly despite inevitable link failures..
Test environment and architecture
The testing was done on a live 512-GPU cluster in production at the data center of WhiteFiber, an AI and HPC infrastructure solution provider.
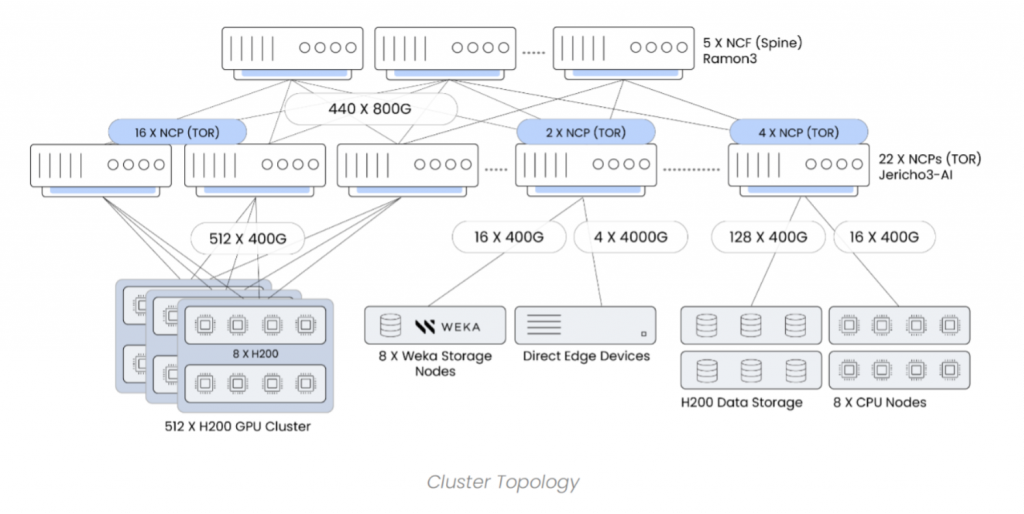
Cluster topology:
- Compute: 512 Nvidia H200 GPUs and 8 CPU nodes
- Storage: 8 Weka storage nodes
- Network: 22 NCPs (top-of-rack (ToR) switches) and 5 NCFs (fabric switches), built with Accton NCP5 and NCF2 white boxes, powered by Broadcom Jericho3AI and Ramon3 chipsets
- Software: DriveNets software orchestrating and managing the entire cluster fabric.
Results
Below are NCCL benchmark results for cluster sizes of 128 GPUs and 512 GPUs, covering the four well-known collective communication operations: all-reduce, all-to-all, all-gather, and reduce-scatter.
By any measure, these results are industry-leading, providing a clear view of the performance advantages of DriveNets AI Fabric.
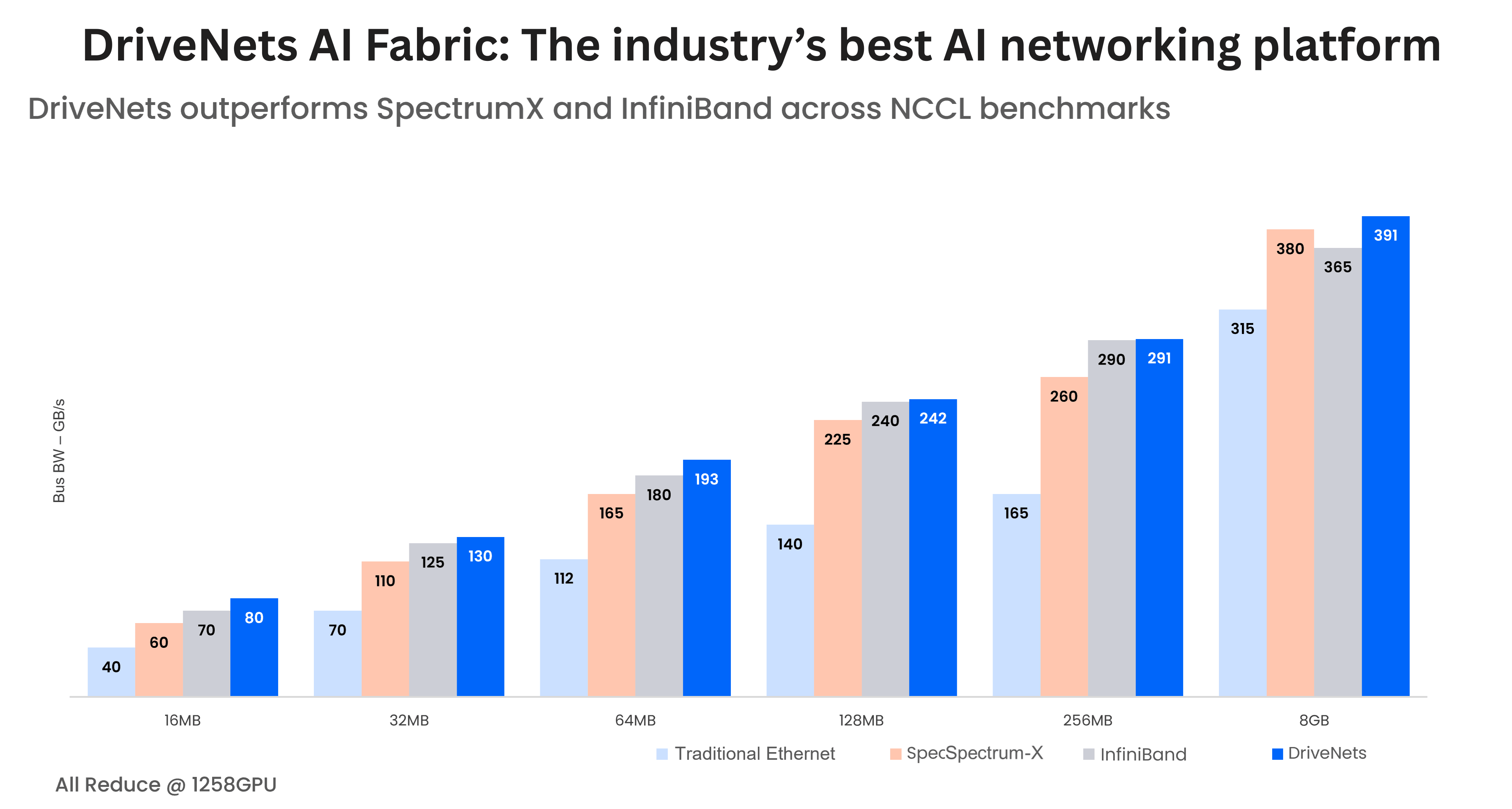
While public results for the competitors’ 512-GPU node architecture aren’t available, DriveNets is publishing our results to provide a transparent performance reference.
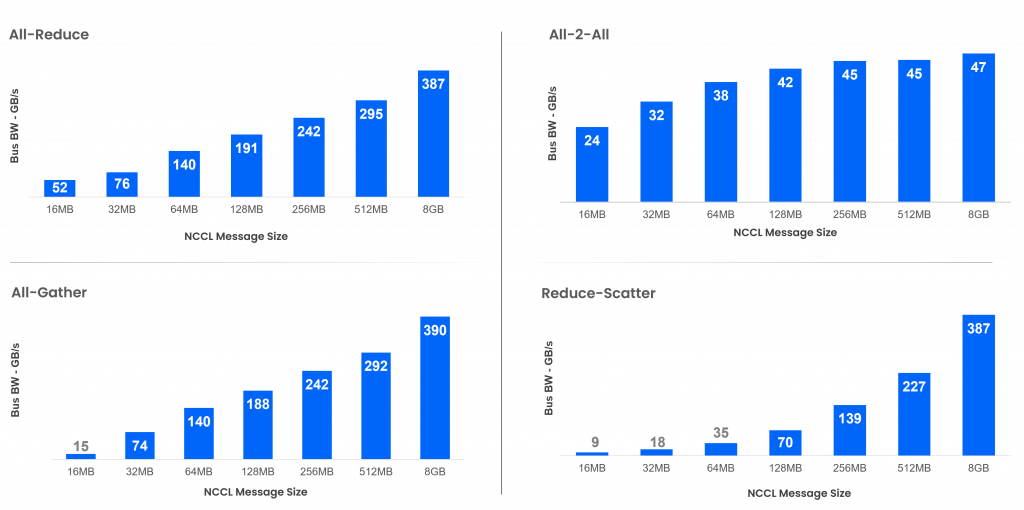
DriveNets Performance Results – 512GPU Cluster (H200, 64 Nodes, ToR Topology)
DriveNets redefines what’s possible for Ethernet in AI infrastructure. DriveNets’ Fabric-Scheduled Ethernet delivers up to 18% better performance than InfiniBand, while maintaining the openness and flexibility of standard Ethernet. Benchmark results make it clear: whether building a large-scale training cluster or scaling a GPU-as-a-service (GPUaaS) data center, DriveNets AI Fabric is purpose-built to meet the demanding needs of large-scale AI workloads.
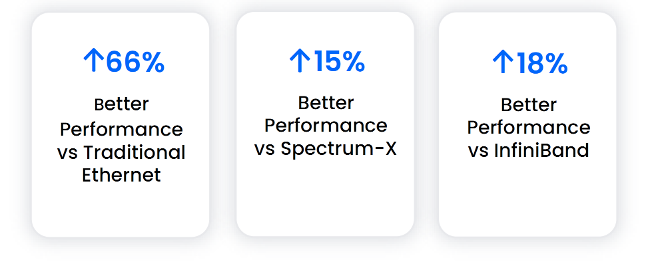
Percentages above represent the average performance gains of DriveNets AI Fabric over competing solutions across all available NCCL message sizes tested.
Key Takeaways
- Networking-not compute-is the main bottleneck in large AI clusters, directly impacting GPU utilization, job completion time, and cost efficiency.
- InfiniBand delivers high performance but locks customers into Nvidia’s proprietary stack, while traditional Ethernet cannot meet AI-scale performance needs.
- DriveNets’ Fabric-Scheduled Ethernet (FSE) replaces “best-effort” Ethernet with a fully scheduled, lossless fabric, delivering predictable low latency at scale.
- Fabric-Scheduled Ethernet (FSE)’s cell-based fabric, receiver-based scheduling (VOQs), and zero-impact failover enable efficient load balancing, congestion elimination, and resilience without complex tuning.
- In a real 512-GPU production cluster, DriveNets outperformed InfiniBand by up to 18% on NCCL benchmarks, proving Ethernet can exceed proprietary alternatives at scale.
Frequently Asked Questions
Why does the network become the main bottleneck in large AI clusters?
As GPU clusters scale to hundreds or thousands of GPUs, inefficient data movement causes expensive GPUs to sit idle, increasing job completion time and cost per million tokens.
How is Fabric-Scheduled Ethernet different from traditional Ethernet?
Unlike best-effort Ethernet, Fabric-Scheduled Ethernet uses coordinated, receiver-based scheduling with cell-based traffic spraying to deliver predictable, lossless, low-latency performance at scale.
How does DriveNets’ Ethernet performance compare to InfiniBand in production?
In a live 512-GPU production cluster, DriveNets’ Fabric-Scheduled Ethernet achieved up to 18% better NCCL performance than InfiniBand across tested workloads.
Related content for AI networking infrastructure
DriveNets AI Networking Solution
Latest Resources on AI Networking: Videos, White Papers, etc
Recent AI Networking blog posts from DriveNets AI networking infrastructure experts
White Paper
Scaling AI Clusters Across Multi-Site Deployments