



|
Getting your Trinity Audio player ready...
|
What is parallelism?
Parallelism is the practice of dividing a task into smaller parts and executing them simultaneously to increase efficiency and reduce total processing time. Parallelism in computing means complex jobs are split across multiple processing units. In the digital world, parallelism is a fundamental principle behind performance scaling, allowing systems to handle larger workloads faster by doing more things at once.
What is parallelism in AI?
In the context of artificial intelligence (AI), parallelism is not just useful—it’s essential. Modern AI models, especially deep learning systems, are resource-intensive and require significant computational power. Training and running these models efficiently demand parallel processing across multiple GPUs, servers, or entire data centers. AI workloads rely heavily on parallelism to reduce training time, improve throughput, and enable scale. Without parallelism, training a large language model or image recognition system could take years.
Why parallelism in AI?
AI models are built with millions or even billions of parameters. Training them involves processing massive datasets and performing repeated matrix operations. Without breaking this work into smaller, simultaneous tasks, even the most advanced hardware would be overwhelmed. Parallelism allows for more efficient use of compute resources, faster model convergence, and the ability to scale AI clusters across hundreds or thousands of nodes. But it also introduces complexity—especially for the infrastructure that must support it.
This is where the network plays a critical role. Each form of parallelism generates unique communication patterns between devices, placing different demands on bandwidth, latency, isolation, and scalability.
What are the main types of parallelism in AI?
Let’s examine four key types of parallelism in AI and how each works within an AI cluster:
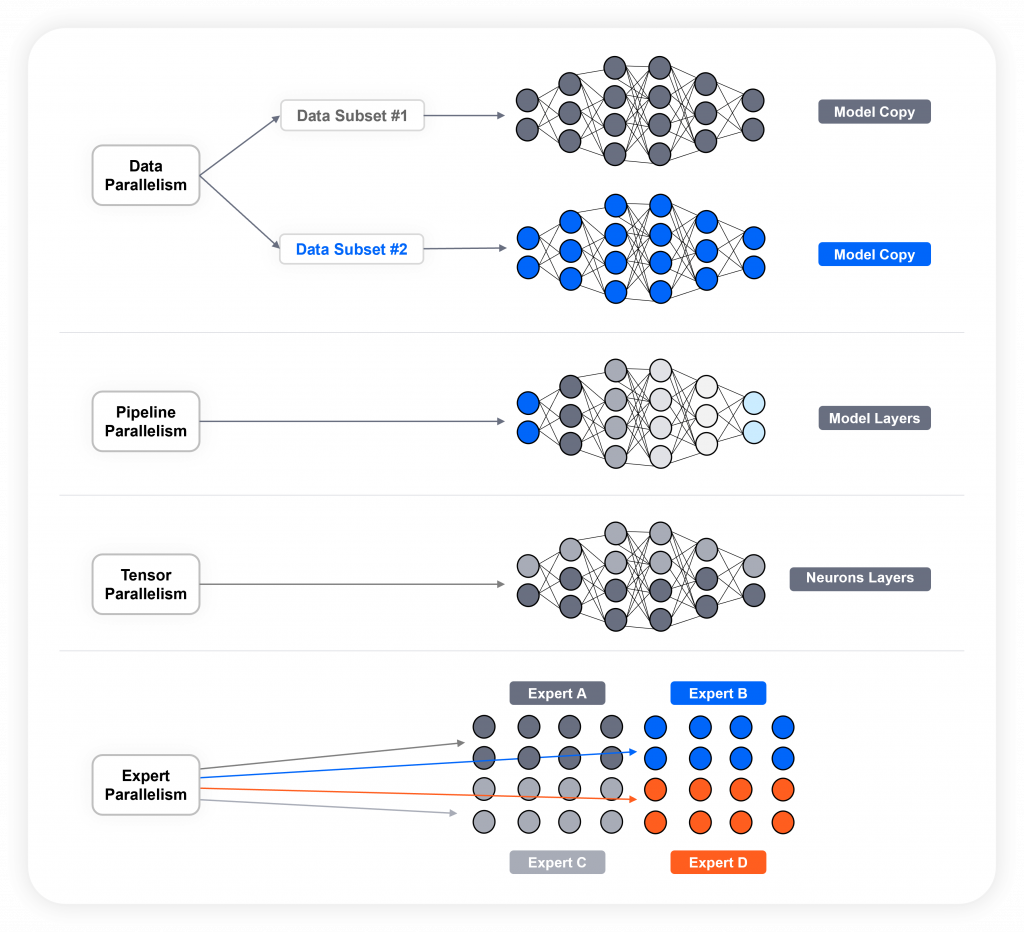
- Data Parallelism
In data parallelism, the same AI model is copied across multiple GPUs or nodes. Each instance processes a different subset of the training data in parallel. After computing gradients, the results are synchronized (typically using collective operations like AllReduce) to update model weights. Data parallelism is most commonly used in deep learning.
Cluster requirement: high-bandwidth, low-latency communication between GPUs/nodes, as synchronization overhead grows with the number of parallel units. - Pipeline Parallelism
Pipeline parallelism splits the model into sequential stages. Each stage is assigned to a different GPU or node. Input data flows through the pipeline, allowing different layers of the model to process different batches simultaneously. Pipeline parallelism reduces memory footprint on each device.
Cluster requirement: Careful scheduling to keep all stages busy, since massive communication happens between consecutive stages. - Tensor Parallelism
Tensor parallelism breaks up individual tensors (like weights or inputs) and distributes the pieces across multiple devices. Matrix operations are performed in parallel across these tensor slices.Tensor parallelism is used when a model or tensor is too large to fit on a single device.
Cluster requirement: Tight coordination and high-speed communication, due to the super high synchronization requirements implemented within GPUs located in the same server. - Expert Parallelism
Expert parallelism is used in mixture of experts (MoE) models, where only a few sub-models (experts) are activated per input. These experts are distributed across different devices and execute in parallel based on a routing function. Expert parallelism runs on different devices, selected dynamically per input.
Cluster requirement: A network that can handle dynamic, uneven traffic patterns, since sparse activation reduces compute load.
How does parallelism impact networking?
Each parallelism type affects the network differently:
- Data Parallelism
- Network impact: heavy use of collective communication (e.g., AllReduce)
- Requirement: high throughput, predictable and low-latency, lossless network
- Challenge: synchronized updates can bottleneck if network is congested
- Pipeline Parallelism
- Network impact: point-to-point traffic between sequential stages
- Requirement: consistent low latency between stages
- Challenge: latency spikes causing pipeline bubbles and stall processing
- Tensor Parallelism
- Network impact: fine-grained, high-frequency interconnect
- Requirement: extremely low-latency fabric with deterministic performance
- Challenge: accuracy and speed impacted by any jitter or loss
- Expert Parallelism
- Network impact: sparse, dynamic traffic patterns across GPUs
- Requirement: fabric flexibility, high bandwidth, and fair resource sharing
- Challenge: irregular loads across nodes demanding strong isolation and congestion control
AI parallelism comparison: Network patterns & requirements
Parallelism Type | Network Pattern | Key Requirement | Main Challenge |
|---|---|---|---|
| Data Parallelism | Collective (AllReduce) | High bandwidth, low latency | Synchronization bottlenecks |
| Pipeline Parallelism | Point-to-point | Consistent low latency | Avoiding idle pipeline stages |
| Tensor Parallelism | Fine-grained interconnect | Deterministic, lossless transport | Sensitivity to jitter and loss |
| Expert Parallelism | Sparse, dynamic routing | Adaptive, fair resource sharing | Uneven traffic distribution |
Make your network an enabler – not an inhibitor
Legacy networks or standard Ethernet fabrics often struggle to meet these demands without heavy tuning or overlay complexity. That’s why AI infrastructure requires a purpose-built network fabric that delivers deterministic performance, strong isolation, seamless failover, and dynamic scalability.
At DriveNets, we believe the network should be an enabler, not an inhibitor. A high-performance, scheduled fabric designed for AI workloads ensures that all types of parallelism operate efficiently—with no need to tune the network to fit the workload.
Frequently Asked Questions
How do different AI parallelism methods impact network requirements?
Data parallelism involves replicating models across GPUs, requiring high-bandwidth communication for synchronizing gradients. Model parallelism splits models across GPUs, necessitating low-latency connections for layer-to-layer data transfer. Expert parallelism activates subsets of model components, demanding flexible and efficient routing to handle dynamic communication patterns.
Why is standard Ethernet insufficient for AI workloads?
Traditional Ethernet lacks the deterministic performance needed for AI tasks, often resulting in latency variability and packet loss. These issues can lead to underutilized GPUs and prolonged training times.
How does DriveNets’ solution address these networking challenges?
DriveNets introduces a scheduled, lossless Ethernet fabric that ensures predictable, low-latency communication. By employing techniques like cell spraying and virtual output queuing, it effectively manages diverse AI parallelism strategies, enhancing overall cluster performance.
Key Takeaways
- AI workloads use different forms of parallelism—data, model, pipeline, and expert parallelism—each placing unique demands on network architecture.
- Data parallelism requires high bandwidth, as it involves synchronizing gradients across all GPUs after each training step.
- Model and pipeline parallelism are latency-sensitive, needing fast, consistent connections between GPUs to maintain training efficiency.
- Expert parallelism introduces irregular, dynamic traffic patterns, requiring flexible routing and efficient traffic management at scale.
- DriveNets’ lossless Ethernet fabric meets all these demands, delivering the predictable, scalable, and high-performance networking AI clusters need—without relying on proprietary solutions.
Related content for AI networking infrastructure
DriveNets AI Networking Solution
Latest Resources on AI Networking: Videos, White Papers, etc
Recent AI Networking blog posts from DriveNets AI networking infrastructure experts
NeoCloud Case Study
Highest-Performance Unified Fabric for Compute, Storage and Edge