



|
Getting your Trinity Audio player ready...
|
In practice, modern inference juggles many users at once. Prompts are getting longer, and the system has to stay stable when traffic spikes or remains elevated for hours. The question is not whether a single request runs fast, but whether the system maintains throughput and responsiveness as concurrency increases.
This blog post looks at how the AMD Instinct MI355X behaves under that pressure, and why a full-system approach is critical to making those results hold in production.
In our joint work with AMD built around the AMD Instinct family, DriveNets and AMD evaluated how the MI355X behaves under production-like inference conditions. The tests focused on three dimensions that directly impact production readiness and operational efficiency:
- Scaling efficiency with realistic concurrency: how throughput, TPOT (time per output token), and per-user performance behave as concurrency rises
- Predictable responsiveness under load: whether TTFT (time to first token) and end-to-end latency stay bounded and stable under realistic, interactive serving conditions
- Architectural flexibility at cluster scale: how disaggregated prefill and decode designs can be tuned for responsiveness versus throughput without hitting instability cliffs
What’s critical here is that these results do not come from GPU specs alone. The complete architecture must be aligned across compute, networking, NICs, and software, all working and tested together. DriveNets’ role is to ensure that the MI355X can sustain its performance under real concurrency, real traffic patterns, and long running production workloads, not only in isolated benchmarks.
| Methodology and notes | |
|---|---|
| Model | DeepSeek-R1 |
| Input/output | 8k-token input and 1k-token output |
| Precision | FP8 |
| Server runtime | SGLang |
| Test scope | Single-node (8x MI355X) and multi-node (9 nodes, 72 GPUs) configurations evaluated in our joint testing environment |
Better scaling where it matters
In real-world AI, LLM inference does not just handle one person at a time. It gets hit by hundreds of simultaneous requests. The goal is to scale without choking under the pressure, so user experience stays consistent even when the system is under increasing pressure.
In our single-node testing using DeepSeek-R1 on one server with 8x AMD Instinct MI355X GPUs (8k-token input, 1k-token output, FP8 precision, SGLang), the MI355X scaled more efficiently as concurrency increased. Essentially, while Instinct’s competitors might keep up with a single user, the MI355X pulled ahead on the metrics that actually determine how many users can be served per node. The MI355X also benefits from 288 GB of HBM3E, which helps reduce memory bottlenecks even at peak load.
As can be seen in the following graphs, as concurrency increases the MI355X delivers:
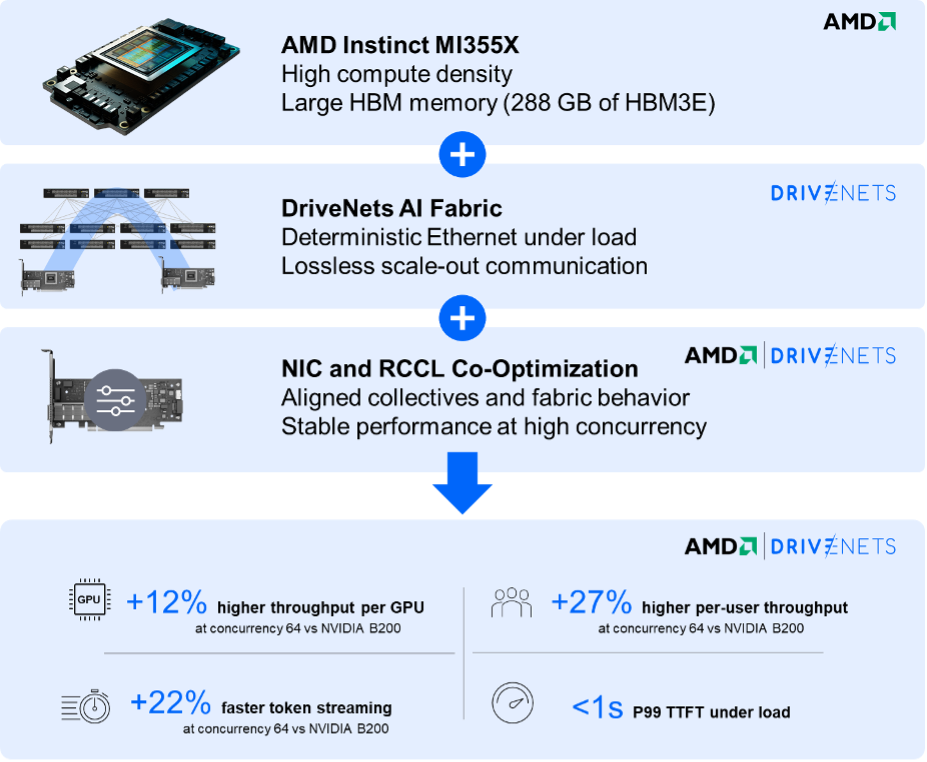
- 12% higher throughput per GPU: 1,668 tokens/sec/GPU at concurrency 64 on MI355X vs 1,485 on Nvidia B200
- 22% faster token streaming (lower TPOT): median 35.1 ms at concurrency 64 on MI355X vs 45.2 ms
- Less per-user slowdown: about 28 tokens/sec/user at concurrency 64 on MI355X vs 22 in the comparison
This means that at higher loads, MI355X-based workloads will be able to serve more users per node, delaying the need to scale out, and reducing cost per served request.
 measures peak throughput under saturation")
Infinite request rate (rr=inf) measures peak throughput under saturation
At higher concurrency, inference efficiency becomes a system-level problem. GPU utilization increasingly depends on how well collective communication and memory movement behave under pressure. DriveNets ensures that scaling does not stall due to communication inefficiencies, allowing the MI355X to convert concurrency into usable throughput rather than idle cycles.
Predictable responsiveness under load
In AI inference, there is a constant trade-off between throughput and latency. Throughput alone is not enough. For users, responsiveness matters. Users get frustrated when TTFT is slow and it takes too long to start receiving output. Operations teams also hate unpredictable latency because it makes it hard to meet service-level objectives (SLOs) and turns hardware planning into a guessing game.
That’s why, in our testing, we didn’t just push the system to its breaking point to find a theoretical maximum. We evaluated how it actually behaves under real-world pressure. Using DeepSeek-R1, we tested at a steady rate of 32 requests to reflect real-life interaction, focusing on TTFT and end-to-end latency performance as concurrency climbs.
Two points to remember before deciphering the graphs below:
- Regarding TTFT thresholds, under ~500 ms feels near-instant, while under 1 second (1000 ms) is generally acceptable for interactive inference.
- P99 TTFT means the value below which 99% of requests fall.
=32 evaluates TTFT under production-like load")
Request rate (rr)=32 evaluates TTFT under production-like load
From the results shown in the graphs above, TTFT stayed bounded even as concurrency increased, with P99 TTFT remaining below 1 second. End-to-end latency also grew smoothly rather than spiking unpredictably. This consistency is essential for production inference, where a small number of slow responses can dominate perceived performance.
This bounded behavior does not happen by accident. Under load, many inference systems fail not because of poor GPU performance, but because network congestion and retransmissions amplify tail latency. DriveNets removes this variability by aligning the networking fabric, NIC behavior, and RCCL collectives with inference concurrency, keeping GPUs productive as load increases.
This kind of predictable behavior is what makes a system deployable at scale. It separates systems that look good in labs from systems that can handle real production traffic.
Flexible performance at cluster scale
At multi-node scale, inference is more than just scaling out and adding servers. It is a fundamental architectural challenge. Since LLM inference has two distinct phases, prefill (compute-heavy) and decode (memory-bound), simply stacking more hardware creates inefficiencies. One resource sits idle while the other becomes a bottleneck.
In our multi-node testing environment, we evaluated multi-node DeepSeek-R1 inference on a 9-node cluster (72 GPUs total) using a disaggregated prefill and decode design, testing two splits:
- 5 prefill / 4 decode (5P-4D), optimized for latency
- 4 prefill / 5 decode (4P-5D), optimized for throughput
The goal was not to optimize for a single benchmark, but to demonstrate that the system remains stable and predictable as the prefill–decode balance changes.
This flexibility depends on predictable network behavior. Changing the prefill and decode balance shifts traffic patterns significantly. DriveNets enables this tuning by providing a lossless, scheduled Ethernet fabric where changes in communication patterns do not result in congestion collapse or instability.
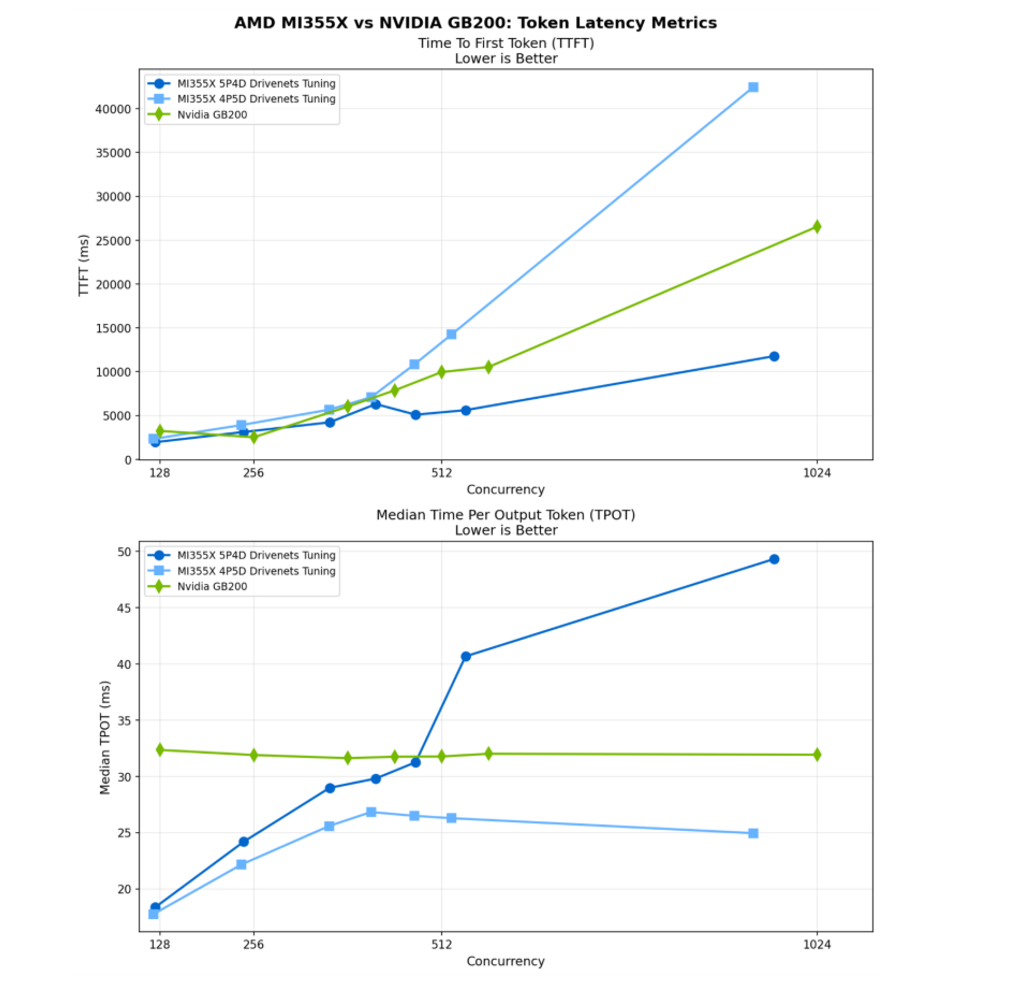
From the results, MI355X-based disaggregated configurations were competitive with, and often outperformed, the Nvidia GB200 baseline, particularly at low-to-medium concurrency levels where most production services operate.
Even at higher concurrency, performance does not hit an instability cliff. Instead, it follows the tuning targets that were set. This is a direct result of treating the network as a first-class part of the inference system rather than a best-effort transport layer.
Why the full system matters
The competitive edge of the MI350 series stems from a full-system approach: high-capacity memory, efficient scale-up and scale-out communication, and an optimized software and networking stack designed to keep GPUs productive under load.
On the GPU side, the MI355X is purpose-built for demanding, long-context inference with 288 GB HBM3E and 8 TB/s memory bandwidth, reducing memory pressure and allowing larger models to fit on fewer accelerators.
However, raw GPU capability is only as effective as the fabric connecting it. Scale-up relies on AMD Infinity Fabric links delivering 1.07 TB/s of aggregate bandwidth. Scale-out depends on the network remaining predictable as traffic grows.
DriveNets ensures that the network does not become a silent bottleneck. By integrating AMD Pensando Pollara 400 AI NICs with intelligent packet spray and path-aware congestion control, the fabric maintains high throughput without sacrificing tail latency.
The AI cluster orchestrator further ensures that what gets deployed in production matches the validated configuration used in testing. Provisioning, validation, and benchmarking are automated, closing the gap between lab performance and real-world behavior.
The bottom line: combining AMD’s capabilities with DriveNets full-system approach
For modern AI inference, efficiency under load is the true measure of success. The results from this joint testing effort show that the MI355X is more than a list of high-end specs. It is a platform that converts heavy concurrency into usable throughput while keeping token latency bounded and predictable.
By combining AMD’s capabilities with the DriveNets full-system approach, it’s clear that a solution built on AMD Instinct can easily handle the real-world demands of running modern AI inference in production.
Key Takeaways
- Scales Efficiently Under Real Concurrency
The MI355X converts rising concurrency into higher usable throughput, delivering more tokens per second per GPU with less per-user slowdown — enabling more users per node at lower cost. - Keeps Latency Predictable Under Load
Even as traffic increases, TTFT and end-to-end latency remain bounded and stable, ensuring consistent user experience and easier SLO management. - Flexible, Stable Performance at Cluster Scale
Disaggregated prefill/decode architectures can be tuned for latency or throughput without triggering instability, thanks to a predictable, system-aligned network fabric. - Full-System Design Drives Production Readiness
Sustained inference performance depends on aligning GPUs, memory, networking, NICs, and software — not just raw accelerator specs.
Frequently Asked Questions
How does the MI355X perform under real-world concurrency?
In joint testing with DeepSeek-R1, the MI355X scaled efficiently as concurrency increased, delivering higher throughput per GPU, faster token streaming (lower TPOT), and less per-user slowdown — meaning more users can be served per node without sacrificing performance.
Does higher throughput come at the expense of latency?
No. Under production-like request rates, the system maintained bounded P99 TTFT (under 1 second) and smooth end-to-end latency growth, ensuring predictable responsiveness even as load increased.
Why is a full-system approach necessary for production inference?
GPU specs alone are not enough. Sustained performance under load depends on aligning compute, memory, networking fabric, NIC behavior, and orchestration so that concurrency translates into stable, usable throughput rather than bottlenecks or latency spikes.
Related content for AI networking infrastructure
DriveNets AI Networking Solution
Latest Resources on AI Networking: Videos, White Papers, etc
White Paper
Scaling AI Clusters Across Multi-Site Deployments