



|
Getting your Trinity Audio player ready...
|
It’s time to rethink our approach to latency – not as an inevitable limitation but as a solvable challenge. By dispelling this ‘unsolvable latency’ myth, we can unlock new levels of performance and efficiency in today’s most demanding applications, from real-time AI inference to very large AI training workloads.
Latency – the delay in data transfer between systems – is a critical factor in AI back-end networking. Latency impacts the efficiency of data processing and model training, and it plays a significant role in the overall performance of AI applications.
But not all latency is created equal. In AI back-end networking, different types of latency metrics exist, including head, average, and tail latency. Understanding these latency types and their effects on packet loss and packet retransmission is essential for optimizing AI system performance.
Why Is Latency Critical for AI Workload Performance?
The AI workload cycle is built from three main recuring steps. In the compute stage, the GPUs are executing the parallel compute instructions. In the notification stage, the results of computation are sent to other GPUs according to the collective communication pattern. Lastly, in the synchronization stage, the compute stalls until data from all GPUs arrives. One can easily understand that the slowest path (also referred to as worst-case tail latency) is the one that most influences job completion time (JCT).
Types of Latency in AI Back-End Networking
Head Latency in AI Networking
Head latency refers to the minimum latency observed in data transfer. It represents the lowest delay between when a packet is sent and received. In other words, it corresponds with the fastest response time possible in the network. Head latency is essential for establishing the baseline performance of a network, particularly in high-speed, low-latency environments where the fastest response time is critical.
Example: Head latency might be the delay of a packet sent through a low-traffic network path. This low latency is achievable under ideal conditions but might be rare in production environments with varying network loads.
Average Latency
Average latency is the mean delay of data packets over time. This metric provides a general sense of how quickly data is typically transmitted and is often used as a benchmark to measure general network performance. However, average latency alone does not tell the full story, as it does not account for outliers or occasional high delays. In AI applications, where consistent performance is crucial, relying solely on average latency can be misleading because it doesn’t represent worst-case scenarios.
Example: In a distributed AI training environment, if most packets arrive within 10 milliseconds, but a few take much longer, the average latency will be skewed. A lower average latency generally signals good network health, but it’s important to also monitor tail latency to understand variability.
Tail Latency
Tail latency measures the delay experienced by the slowest packets, typically expressed as a high percentile (like the 95th or 99th percentile) of response times. Tail latency is essential in AI networking because it highlights potential bottlenecks and delays that could impact performance. AI applications are particularly sensitive to tail latency because tasks often involve processing large amounts of data where even a few delayed packets can disrupt the entire process.
Example: In a neural network training session, if a few packets experience high tail latency due to network congestion, they could delay the overall training time, making tail latency a key concern in network optimization.
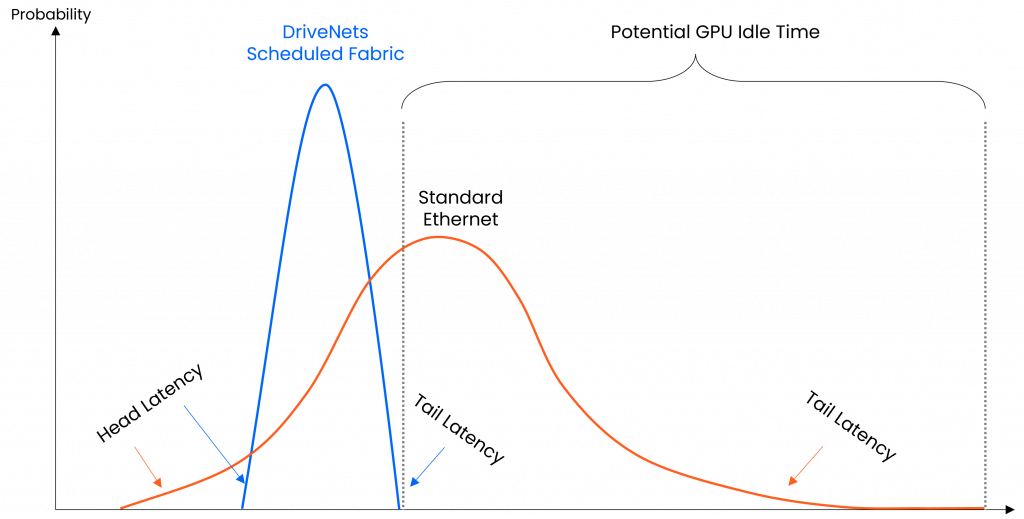
Optimizing latency for best JCT performance – trading off a bit of higher head latency for less variance and lower tail latency
Effects of Latency on Packet Loss and Retransmission
In AI networking, latency doesn’t just affect response times; it also has significant implications for packet loss and retransmission, which are both crucial in maintaining data integrity and consistency.
Packet Loss and Latency
Packet loss occurs when data packets fail to reach their destination, often due to congestion, errors in transmission, or inadequate network capacity. High latency can increase the likelihood of packet loss, particularly in time-sensitive AI applications. When latency is high, packets might “time out” or be dropped, especially when multiple systems are attempting to communicate simultaneously.
Packet loss can significantly impact model training and inference performance by introducing additional latency. When a packet is lost, the application layer must retransmit it, and the time required for retransmission directly adds to the GPUs’ idle time, reducing overall efficiency.
Packet Retransmission and Latency
Packet retransmission is a process in which lost or corrupted packets are resent to ensure data integrity. High latency increases the frequency of packet retransmissions because time-sensitive data might not arrive as expected. Each retransmission adds additional delay, further increasing the latency experienced by AI applications. In scenarios where data is heavily interdependent – as in distributed AI model training – repeated retransmissions can significantly slow down the entire training process.
Consider a case where an AI model requires data from several distributed servers. If the network experiences latency spikes leading to packet retransmissions, each delayed data packet can slow the entire system, affecting model convergence and increasing computational costs.
Go-Back-N ARQ – a Double-Edged Sword
As AI network efficiency is critical, advanced protocols like the Go-Back-N ARQ are commonly implemented in AI network routers. Go-Back-N is an automatic repeat request (ARQ) protocol that allows multiple packets to be sent (determined by a configurable window size) before receiving acknowledgment (ACK) for the first packet in the sequence. This protocol enhances efficiency by reducing the number of ACKs required in the network, thus minimizing network overhead.
However, Go-Back-N can significantly impact AI network JCT because it requires retransmission of all packets in the window, even if only a single packet is lost. If an error or loss occurs in one packet, the protocol mandates that all packets within the specified window (N packets) be resent. This can introduce delays and negatively affect overall performance in time-sensitive AI tasks.
Latency in AI Inference and Training Workloads
Latency in Inference Workloads
Inference involves using a trained model to generate predictions or make decisions based on new data, with latency being a critical factor for ensuring fast, responsive results. Inference tasks are often real-time or near-real-time, meaning they must deliver outputs almost instantaneously to be effective.
Inference is widely used in applications such as virtual assistants, recommendation engines, autonomous driving, and financial trading, where response time directly impacts user experience and overall system performance. Low latency ensures near-instantaneous results, which significantly enhances user satisfaction and system responsiveness.
Of the three types of latency – head, average, and tail – the “worst-case” tail latency is particularly important in inference tasks. High tail latency can create delays and inconsistent user experiences, ultimately limiting model performance. Therefore, minimizing tail latency is crucial for optimizing AI inference tasks, as it sets the benchmark for maximum response time and directly influences user satisfaction and system reliability.
Latency in AI Training Workloads
Training is typically done in iterations where data is processed repeatedly to improve model accuracy. High latency during data transfer can prolong each iteration, significantly extending the job completion time. In training workloads there is a very high amount of data transfer between the GPUs as the processing tasks are distributed to multiple GPUs and the parallel processing must be synchronized. It’s important to note that, once again, the tail latency will have the highest effect on the JCT of the training session as the synchronization mechanism waits for the processed data of the last GPU.
In summary, reducing tail latency in training workloads leads to faster job completion time, better resource utilization, and improved model iteration cycles. This is crucial in accelerating model development, lowering costs, and quickly adapting models in evolving environments.
Optimizing Tail Latency in Ethernet Fabric
Understanding and managing latency, packet loss, and retransmissions are crucial for high-performance AI back-end networking. While standard Ethernet has multiple key advantages, it is known as a lossy protocol, with unpredictable latency and frequent packet loss.
To optimize Ethernet for AI back-end cluster networking, there is a need to “convert” the lossy nature of the network into a lossless nature with predictable tail latency. The industry is offering a few solutions to this challenge. The first is based on telemetry – monitoring the network load and the different buffers in order to reduce the latency and the packet losses. The second solution is based on scheduled fabric that totally eliminates packet losses and offers predictable tail latency.
DriveNets Network Cloud-AI – Scheduled Ethernet Fabric
DriveNets Network Cloud-AI solution delivers a network optimized for AI workloads with a lossless, predictably scheduled Ethernet fabric. While the scheduling mechanism adds a minimal amount to the baseline head latency, it significantly enhances both average and tail latency performance.
The scheduled fabric, combined with advanced cell-spraying technology, which fragments packets into cells and distributes them across all network links, enables highly efficient load balancing across the back-end network. This approach minimizes bottlenecks that can cause packet loss and retransmissions, ultimately reducing tail latency and providing a more stable, responsive network environment for AI workloads.
Ensure timely data delivery across AI clusters: Minimize disruptions and optimize performance
In AI networking, tail latency plays the most significant role in determining network efficiency, GPU utilization, and overall performance, especially for distributed and time-sensitive AI workloads. While head, average, and tail latency each provide valuable insights into network behavior, tail latency typically reveals the most critical bottlenecks that can disrupt performance. High tail latency often results in increased packet loss and retransmissions, compounding delays and impacting AI model training and inference processes.
By optimizing tail latency, organizations can establish robust, reliable AI networking infrastructures that minimize disruptions, improve performance, and ensure consistent, timely data delivery across AI clusters. The DriveNets Network Cloud-AI solution offers an optimal approach for AI back-end networking. As an Ethernet-based solution with advanced scheduling fabric, it ensures the lowest average and tail latency, delivering superior job completion times, maximizing network utilization, and driving an optimal return on investment (ROI).
Key Takeaways
- In AI back-end networking, different types of latency metrics exist, including head, average, and tail latency.
- In AI networking, tail latency plays the most significant role in determining network efficiency, GPU utilization, and overall performance, especially for distributed and time-sensitive AI workloads.
- Workload balance: the slowest path (also referred to as worst-case tail latency) is the one that most influences job completion time (JCT).
- Packet loss and retransmission: Latency has significant implications for packet loss and retransmission – both crucial in maintaining data integrity and consistency.
- Inference tasks:High tail latency can create delays and inconsistent user experiences, ultimately limiting model performance.
- Performance: Understanding and managing latency, packet loss, and retransmissions are crucial for high-performance AI back-end networking.
- Scheduled Ethernet Fabric: DriveNets Network Cloud-AI solution delivers a network optimized solution for AI workloads with a lossless, predictably scheduled fabric – adding a minimal amount to the baseline head latency, and significantly enhancing both average and tail latency performance.
- Optimizing tail latency: allows organizations to establish robust, reliable AI networking infrastructures that minimize disruptions, improve performance, and ensure consistent, timely data delivery across AI clusters.
Frequently asked questions
- Why is latency a critical factor in AI networking performance?
Latency, the delay in data transfer between systems, significantly impacts AI workload efficiency. In distributed AI tasks, especially during training and inference, high latency can lead to increased job completion times (JCT) and underutilization of GPU resources. Minimizing latency ensures timely data delivery, optimal synchronization across GPUs, and overall improved system performance. - What are the different types of latency in AI back-end networking?
Head Latency: The minimum observed delay in data transfer, representing the fastest response time under ideal conditions.
Average Latency: The mean delay of data packets over time, providing a general sense of network performance.
Tail Latency: Tail latency is crucial as it affects synchronization in AI workloads, where the slowest data packet can delay the entire process - How can AI networks optimize tail latency to improve performance?
Optimizing tail latency involves strategies like implementing a scheduled Ethernet fabric, which ensures predictable and uniform data delivery across the network.
Related content for AI networking architecture
eGuide
AI Cluster Reference Design Guide