


Are specific monitoring capabilities required? How do you attain visibility and simplicity for large scale systems? Does a traditional NMS system alone meet the needs of the new model? Can it cope with the challenges associated with a disaggregated network? Is a Network Management System (NMS) still needed at all?
Service and cloud providers need a management system to handle the operational challenges that come with disaggregation:
- Managing all the network elements
- Identifying deficiencies at a granular monitoring level
- Preventing manual errors
- Taking fast corrective actions
At DriveNets, we designed a new management system to address the unique challenges that service and hyperscale cloud providers face when deploying, integrating and managing a disaggregated network.
The Dubious Reputation of NMS Systems
When considering an NMS system for fault management to track alarms, events and network issues, what comes to mind? You probably imagine complex, slow, primitive UX-based, clumsy machines that ruled NOCs back in the nineties. We even hear that there is no need for another separate system and that sending alarms and events to the legacy NMS system is good enough.
The new distributed disaggregated network model is built for extreme growth, rapid service innovation and economic profitability. It comprises several levels of disaggregation: hardware and software, router architecture, data and control planes. It involves operating hundreds of white boxes, each with different functionality (for example, packet forwarding, control plane functions, fabric, etc.) as a cluster – a single logical entity.
Traditional NMS systems are limited in the sense that they supply a “flat” view of the different domains:
- Fault management: alarm aggregation is carried out without consideration of the unique disaggregated structure
- Network discovery: presents IP entities but cannot detect and visualize how these entities are grouped together to create unified virtual functions
- Service management: does not take into account resource allocation, scaling and auto-growth where needed, diminishing the efficiency of the end-to-end service provisioning
In many cases, a traditional NMS system can hardly cope with all these domains and several systems or NMS modules must be used. A new type of NMS system is needed for handling the unique needs of distributed disaggregated networks. This is partly what motivated us to develop our own solution: DriveNets Network Orchestrator (DNOR).
DNOR’s Unique Fault Management Capabilities
The top concern for most operators in network troubleshooting is that it must be quick, efficient and possibly automated to ensure maximum network availability. DNOR visualizes the Network Cloud elements and exposes network management and operations interfaces to the DNOR user interface or third-party systems, enabling all network management domains to work in synch.
DNOR enjoys the advantage of being ‘virtually’ tightly integrated (but not coupled!) into the Network Cloud elements, enabling access to special and specific system occurrences reflected in system alarms, events, notifications, etc.
Existing fault management solutions cannot access or extract the non-standard indications, and even if raised, events are simply forwarded to such northbound interfaces. Identifying valuable and meaningful insights requires developing in-house business logic – something that is already integrated in DNOR.
For example, in a network cluster entity, the specific indicators may be auto-detect cable errors, internal interface faults, bad traffic, or traffic distribution anomalies across the cluster. Logical insights may be correlating hardware events from the data center location, indicating a power failure in a specific rack. Another example may be recommending changing a destination port, diverting traffic to offload network bottlenecks, or blocking ingress traffic if the system observes a traffic flood that may result from malicious network attacks.
DNOR’s Fault Management Architecture
The fault management capability introduced in the DriveNets Network Orchestrator consists of several layers that optimize the system stack, providing an extraordinary experience for end-users.
Cluster Visibility
DNOR presents a comprehensive multi-element cluster in a simple graphical manner and provides the ability to navigate between the different components and check their status. The ‘Topology View’ interface presents the connectivity, software packages installed, and faults on the corresponding interfaces. On the one hand, it presents the cluster’s segmentation in its underlying parts and the overall functionality – a capability not available in today’s NMS (which just shows a flat view without the logical interconnections).
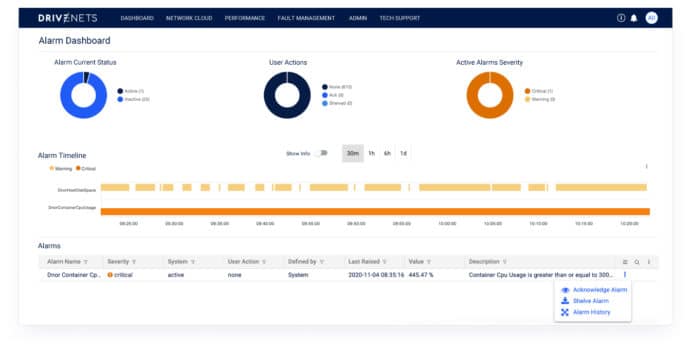
Alarm Management
An alarm represents an undesirable state in cluster nodes or in the orchestrator itself. Metadata is added to each alarm indicating the severity, ID, component in which it was originated, date and time, etc. Alarms are reflected in the orchestrator GUI and may be acknowledged, filtered and exported to a northbound via standard interfaces (REST API).
The ability to set “user-defined” alarms is essential. An interesting occurrence is identified quickly by setting up a personal notification for a specific event or group of events coming from the nodes. This capability is not common in most traditional NMS systems. Furthermore, even where it is, it requires a deep understanding of the disaggregated architecture since the notification options are usually not given out-of-the-box.
Archive Management
Archive management means reviewing and logging alarms and actions for long term storage and post-analysis. There are many reasons for doing this:
- auditing and validating policies like security
- ensuring regulations and compliance policies
- analyzing network anomalies
This layer also includes the information required for debugging purposes (internal and external) such as technical support and R&D packages, including active and history of alarms logs, Syslog, gRPC statistics, counters, etc. DNOR enables auto-scale to adapt to rapid storage changes and expansions. This is not possible in the traditional NMS designed before the cloud era.
Business Logic
Business logic is the functionality that provides suggestions for corrective actions per fault (including alarms correlation, since a fault may consist of several alarms indicating the same root cause). It can also dynamically add a description per fault or alarm based on pre-experience and heuristics. This valuable info is indexed in a dedicated database and shared with the end customers. This layer also includes network fault insights and even predictions for cases where several notifications may imply that a more severe occurrence is yet to come, based on pre-defined collected data used to set a rule or policy. Since such logic is tailored to the disaggregated architecture, it is also not available in legacy NMS systems.
A Totally New Management Experience for Disaggregated Architecture
With the introduction of layering in a disaggregated approach, DNOR offers a totally new experience with a rich and granular graphical view of the system. The simple and intuitive user interface allows users to get network insights for corrective actions, fault prediction and simple network nodes visibility. The ‘old-fashioned’ NMS definitely does not provide this level of visibility. With the very limited analytical capabilities of legacy northbound collectors, DNOR gives the disaggregated network greater value and automation.
Download White Paper
DNOR – DriveNets Network Orchestrator