



|
Getting your Trinity Audio player ready...
|
Challenges of Traditional AI Fabrics
AI training and inference workloads are communication-intensive gradient exchanges with all-reduce operations and collective communication patterns dominating traffic.
Traditional interconnect approaches often suffer from three limitations:
- Congestion-control overhead: Traditional fabrics (e.g., InfiniBand or standard Ethernet) require complex congestion-control tuning to avoid packet loss and head-of-line blocking. This not only increases setup complexity but also creates significant operational overhead, as networking teams must work extensively to optimize the system
- Cross-domain scaling: As GPU clusters scale beyond a single rack or a single location, many fabrics struggle to maintain lossless, low-latency communication across domains, resulting in reduced throughput and underutilized GPUs.
- Vendor lock-in: Non-Ethernet solutions tie customers into proprietary ecosystems, limiting flexibility, supply-chain diversity, and cost efficiency.
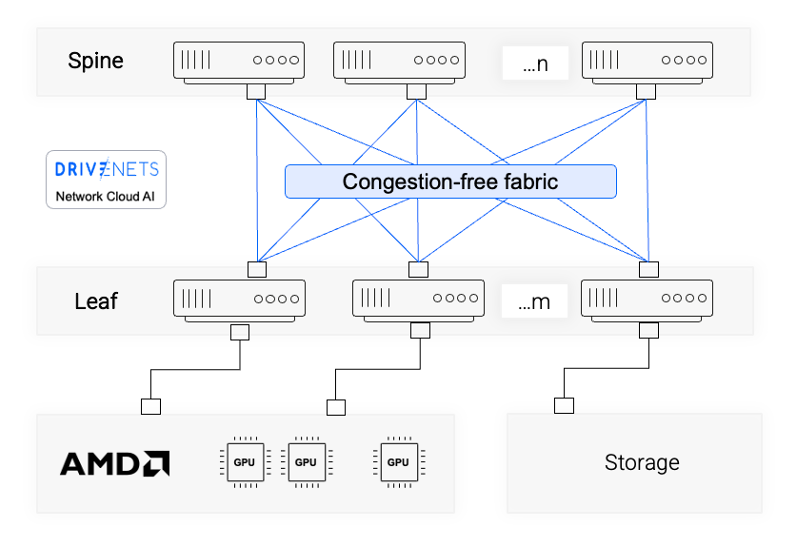
Benefits of DriveNets Solution for AMD-Based Clusters
DriveNets solution ensures highest networking performance regardless of GPU, NIC or Optical components, offering three key benefits when it comes to AMD-based clusters:
- Highest-performance Ethernet fabric: DriveNets’ solution transforms standard Ethernet into a lossless, deterministic interconnect, purpose-built for AI. It ensures zero packet drops across training and inference clusters, maintaining full GPU utilization. The system leverages fabric scheduling to handle extreme collective communication workloads without bottlenecks
- Zero-tuning deployment: Unlike InfiniBand and RoCE-based Ethernet deployments, DriveNets’ solution requires no manual congestion-control tuning. The advanced fabric scheduling solution is based on cell spraying (optimal, out-of-the-box load balancing) and credit-based flows (ensuring no data drops), dramatically reducing complexity and installation time
Lossless scale-out and scale-across geographically
The architecture supports both:
- Scale-out: to other racks within an AI cluster, enabling seamless addition of GPUs while maintaining low-latency, lossless communication
- Scale-across geographically: lossless connectivity between geographically remote locations, up to 100km apart, allowing consistent, deterministic performance
These capabilities ensure optimal job completion time (JCT) performance as workloads grow, both within a single data center and across multiple sites.
Solutions for Scale-Up, Scale-Out, and Scale-Across
The DriveNets solution provides the optimal solution for scale-out and scale-across architectures:
- Scale-Up: AMD Infinity Fabric, Scale-up Ethernet (SUE) and UALink high-speed interconnect communication
- Scale-Out: DriveNets’ FSE-lossless Ethernet fabric leveraging fabric scheduling
- Scale-Across: DriveNets’ FSE-lossless connectivity leveraging deep buffers

AMD’s ROCm Performance
AMD’s ROCm (Radeon Open Compute) platform provides the software foundation for GPU computing. Its RCCL (Radeon Collective Communications Library) delivers collective operations—such as all-reduce, all-gather, broadcast, and point-to-point—that underpin distributed AI training. These operations depend directly on the transport layer of the backend interconnect, whether PCIe, Infinity Fabric, or Ethernet. Performance is highly sensitive to latency and congestion; even small amounts of packet loss force retries and stalls in RCCL, which slow training and drive up costs.
This is where the DriveNets AI Fabric provides a major advantage. By offering lossless, low-latency Ethernet connectivity, it eliminates the need for extensive congestion-control tuning (as required with RoCE), while ensuring deterministic performance at scale. RCCL can automatically leverage RDMA over this lossless Ethernet fabric, bypassing TCP/IP overhead and keeping GPUs near peak utilization. The result is faster TTFT, lower cost per million tokens, and seamless scalability allowing ROCm workloads to scale predictably from hundreds to thousands of AMD Instinct GPUs.
How the Backend Network Affects ROCm
The performance and efficiency of ROCm workloads depend heavily on the backend network:
Latency sensitivity
- AI collectives (especially all-reduce) are highly latency sensitive.
- A backend network with lossless forwarding and low tail latency (like DriveNets AI Fabric) reduces network delays, improving TTFT.
Bandwidth utilization
- If the backend fabric provides high effective bandwidth without packet drops, GPUs maintain near-peak utilization, lowering cost per million tokens.
- ROCm can take advantage of high-throughput interconnects for large tensor exchanges.
Congestion and packet loss
- If the backend fabric experiences congestion or packet drops, RCCL retries or stalls collective ops, which directly slows training.
- A lossless backend (like DriveNets’ Ethernet-based solution) eliminates the need for heavy congestion-control tuning, simplifying deployment and ensuring consistent ROCm performance.
Scalability across racks
- Backend networks that maintain lossless scale-out and scale-across connectivity like DriveNets’ solution allow ROCm workloads to scale seamlessly from hundreds to thousands of GPUs.
Supported AMD GPUs and NICs
The DriveNets AI Fabric is designed to fully support the latest generation of high-performance GPUs and NICs for AI clusters. Today, it seamlessly integrates with the AMD Instinct MI300 and MI350 series (MI300A, MI300X, MI325X, MI350X, MI355X). It also integrates with the AMD Pensando Pollara 400 AI NIC, enabling 400 Gbps Ethernet connectivity with deterministic, low-latency communication critical for large-scale ROCm workloads.
Looking ahead, DriveNets already supports the upcoming AMD MI400 series and the AMD Pensando Vulcano 800 GbE AI NIC, doubling per-port bandwidth to 800 Gbps and extending scalability for next-generation AI clusters. This forward compatibility ensures that organizations deploying AMD GPUs with DriveNets AI Fabric can maximize both current performance and future-proof scaling without disruptive infrastructure changes.
DriveNets Infrastructure Services (DIS)
DriveNets offers unique services to help AMD GPU customers accelelrate time to production and mitigate risks, the DIS team addresses every major phase of the infrastructure lifecycle—design, installation, configuration, testing, performance tuning, and training.
DriveNets Infrastructure Services delivers the following benefits:
- Optimized design: Design and optimize your network architecture for maximum workload efficiency
- Proven in production: Leverage real-world experience with onsite experts who lead complex deployments across Hyperscalers, NeoClouds, & large AI-driven enterprises
- Faster time to value: Accelerate time to production with end-to-end onsite ownership and guidance from design through enablement
Performance and Cost Benefits for AMD Instinct based clusters
DriveNets AI Fabric delivers three key performance benefits:
Lower cost per million tokens
- By maintaining high GPU utilization, every dollar spent on compute produces more output.
- Lossless operation reduces retransmissions, improving throughput predictability.
Fast time-to-first-token
Fast time-to-first-token
- Efficient collective operations minimize startup delays.
- GPUs remain active instead of stalling for data, reducing model warm-up time.
Predictable performance at scale
- Deterministic lossless Ethernet ensures that scaling from 100 GPUs to 10,000 GPUs delivers consistent results.
- No tradeoff exists between locality (scale-out) and global reach (scale-across).
Conclusion: AMD Instinct and DriveNets Ethernet Fabric
AI innovation depends not just on raw GPU power, but on the fabric that ties GPUs together.
With AMD Instinct GPUs providing the compute backbone and DriveNets’ lossless Ethernet fabric ensuring maximum utilization, organizations achieve:
- Industry-leading time-to-first-token (TTFT)
- Lowest cost per million tokens
- Open ecosystem leveraging the broadest hardware and software supply chain
- Investment protection by enabling reusing standard networking skill sets and tools
- Seamless scale to thousands of GPUs
Key Takeaways
- DriveNets turns standard Ethernet into a lossless, high-performance AI fabric, eliminating packet drops and maximizing GPU utilization.
- Zero-tuning deployment simplifies setup with automatic congestion control via cell spraying and credit-based flows.
- Enables seamless scale-out and scale-across connectivity—maintaining low latency from single racks to multi-site clusters up to 100 km apart.
- Integrates natively with AMD ROCm and RCCL, delivering faster time-to-first-token (TTFT) and lower cost per million tokens.
- Supports current and next-gen AMD Instinct GPUs and Pensando NICs, ensuring scalability and future readiness.
- DriveNets Infrastructure Services accelerate deployment, optimize performance, and reduce time to production.
Frequently Asked Questions
How does DriveNets optimize AMD-based AI clusters compared to traditional interconnects?
Traditional AI fabrics like InfiniBand or RoCE-based Ethernet often face congestion, packet loss, and complex tuning challenges. DriveNets solves these with a lossless, Ethernet-based backend fabric that ensures zero packet drops and deterministic performance. It eliminates the need for congestion-control tuning through cell spraying (automatic load balancing) and credit-based flows, enabling faster deployment and higher GPU utilization.
What performance benefits does DriveNets deliver for AMD Instinct GPU clusters?
DriveNet AI Fabric enables:
- Lower cost per million tokens by keeping GPUs fully utilized and minimizing retransmissions.
- Faster time-to-first-token (TTFT) through optimized collective communication.
- Predictable performance at scale, maintaining lossless operation across thousands of GPUs and even between geographically distributed clusters (up to 100 km apart).
How does DriveNets support AMD’s ROCm and future GPU generations?
DriveNets provides seamless integration with AMD’s ROCm platform and RCCL (Radeon Collective Communications Library), ensuring congestion-free, low-latency communication for distributed AI workloads. It currently supports AMD Instinct MI300 and MI350 series GPUs, as well as AMD Pensando Pollara 400 AI NICs, with forward compatibility for upcoming MI400 GPUs and Vulcano 800 GbE NICs, effectively future-proofing AI infrastructure investments.
Related content for AI networking infrastructure
DriveNets AI Networking Solution
Latest Resources on AI Networking: Videos, White Papers, etc
Recent AI Networking blog posts from DriveNets AI networking infrastructure experts
White Paper
Build It Right: AI Cluster End-to-End Performance Tuning