



|
Getting your Trinity Audio player ready...
|
Traditionally, two approaches have shaped how infrastructure teams build AI clusters—rail-optimized and top-of-rack (ToR)-optimized architectures. So, which is better for AI clusters—rail or ToR? Are these truly the only options? Or are emerging innovations reshaping the landscape?
Understanding the two architectures
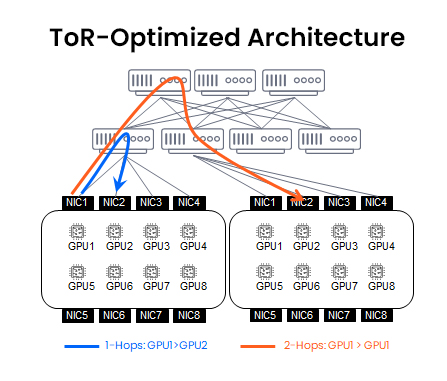
ToR-optimized architecture
ToR designs are common in cloud and hyperscaler’s data centers. In this configuration, each rack has a ToR switch that aggregates all GPUs inside the rack, with upstream spine switches handling inter-rack traffic (Clos).
Benefits
- Simpler to deploy and manage due to better cable management and lower overall cost
- Standardized and familiar to network teams (standard leaf-spine design)
Limitations
- Inter-GPU traffic across racks involves two or more switch hops
- Risk of oversubscription and latency
- Not ideal for AI workloads due to less dynamic GPU to GPU connectivity
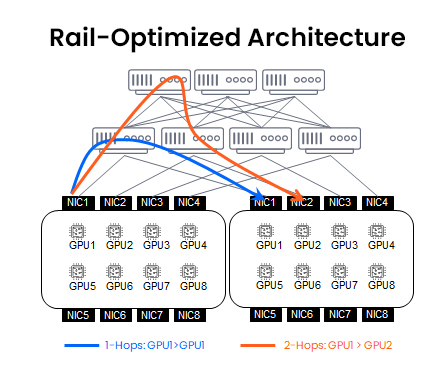
Rail-optimized architecture
Rail architectures usually connect the same-index GPUs (e.g., GPU0 in every rack) horizontally across racks via dedicated switch layers. This design minimizes latency and switch hops—crucial for workloads like collective operations or model-parallel training.
Benefits
- Low-latency, single-hop communication (for same-index GPUs)
- Designed for tightly synchronized AI training workloads
Limitations
- Cross-rail traffic (GPU1 → GPU2) reintroduces multi-hop paths
- High deployment complexity (cabling and more switch layers)
- Managing and scaling such systems can be challenging
It’s clear that both architectures introduce limitations when trying to build complicated and large-scale AI workloads. That’s why a hybrid solution is also being utilized.
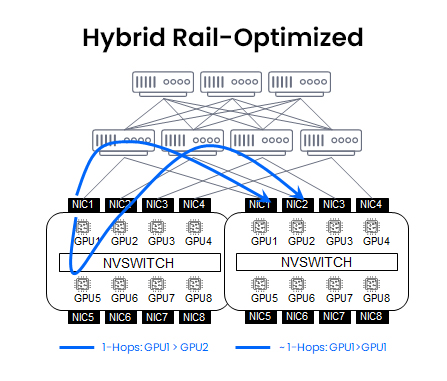
The hybrid approach: Rail + NVLink/NVSwitch
This hybrid architecture combines rail-style interconnects between same-index GPUs across racks with the proprietary NVLink/NVSwitch fabric within each node or DGX pod.
This approach offers ultra-fast intra-node GPU communication (via NVLink/NVSwitch) and reduced latency for structured, index-aligned inter-node GPU synchronization.
However, even this hybrid approach has limitations:
- Rail still breaks at scale, leading to performance and operational challenges
- NVLink/NVSwitch are proprietary, limiting flexibility and long-term vendor choice
- Lack of fabric-native, cluster-wide scheduling limits performance optimization, especially in multi-tenant environments
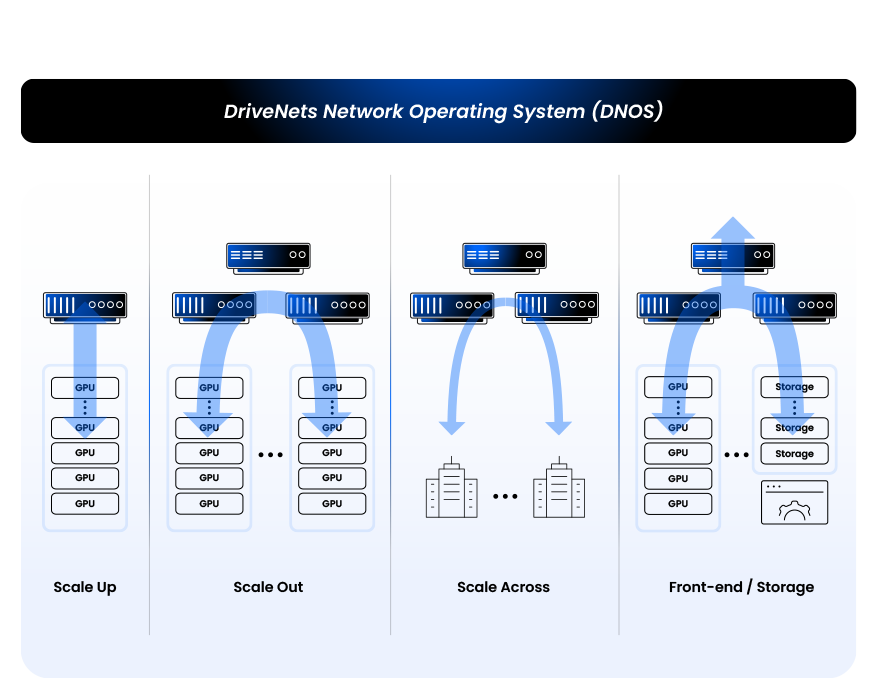
DriveNets AI Fabric: Breaking the ToR ceiling
DriveNets takes a different approach—keeping the simplicity of ToR but transforming it into a fully AI-optimized fabric. By leveraging a scheduled, predictable fabric that connects all ToR switches with 800G of lossless bandwidth, DriveNets makes ToR-based architectures not only viable—but optimal—even at massive scale.
DriveNets’ Fabric-Scheduled Ethernet (FSE) architecture utilizes cell spraying, end-to-end virtual output queues (VOQs) and zero-impact failover, which work together to deliver an optimal networking architecture for large AI clusters.
With FSE, the traditional trade-offs of ToR disappear. You retain the modularity and flexibility of any-to-any GPU connectivity without the cabling complexity and costs typically associated with large-scale rail deployments. At the same time, FSE delivers the lossless, high-performance networking essential for supporting AI workloads at scale.
In short, DriveNets AI Fabric transforms ToR into a fully capable, backend AI fabric that delivers the following key advantages:
- Lossless and predictable connectivity
- Reduced deployment complexity and cost
- Flexible and dynamic any-to-any GPU connectivity
- Inherent multitenancy solution without any complex tuning
While traditional ToR and rail architectures still serve foundational roles, their inherent limitations mean that they struggle to meet the demands of large-scale AI workloads. Hybrid approaches offer some improvements but introduce new complexities and dependencies.
DriveNets AI Fabric enables AI cluster builders to retain the simplicity of the ToR model and gain dynamic, any-to-any connectivity that delivers AI-grade performance, making it ideal for large-scale, high-performance AI environments. Its Fabric-Scheduled Ethernet architecture eliminates ToR’s traditional drawbacks and offers the predictable, lossless connectivity required at scale.
Key Takeaways
- Rail architecture optimizes latency for same-index GPU communication by using dedicated horizontal connections across racks—but it introduces complex deployment and scalability challenges.
- Top-of-Rack (ToR) architectures are easier to deploy and manage, but their multi-hop communication paths can hinder performance in latency-sensitive AI workloads.
- Cross-GPU traffic (e.g., GPU1-to-GPU2) remains a challenge in both models—Rail still requires multi-hop paths for this communication, limiting its overall effectiveness.
- DriveNets introduces a next-gen AI fabric architecture that merges the simplicity of ToR with Rail’s performance benefits—achieving scalable, low-latency connectivity for large AI clusters.
Frequently Asked Questions
- What are the main differences between Rail and Top-of-Rack (ToR) architectures in AI clusters?
Rail architectures connect GPUs with the same index across different racks using dedicated switch layers, enabling low-latency, single-hop communication ideal for synchronized AI training workloads. In contrast, ToR architectures aggregate all GPUs within a rack through a top-of-rack switch, with inter-rack communication handled by upstream spine switches. While ToR designs are simpler to deploy and manage, they can introduce higher latency due to multiple switch hops, making them less optimal for certain AI workloads. - What are the limitations of using a Rail-optimized architecture for AI workloads?
While Rail architectures offer low-latency communication for same-index GPUs, they come with challenges such as increased deployment complexity due to additional cabling and switch layers. Managing and scaling such systems can be difficult, and cross-rail traffic (e.g., communication between GPU1 and GPU2) reintroduces multi-hop paths, potentially impacting performance. - How does DriveNets’ approach differ from traditional Rail and ToR architectures in AI clusters?
DriveNets proposes a hybrid solution that combines the simplicity of ToR with the performance benefits of Rail architectures. Their approach transforms the traditional ToR design into a fully AI-optimized fabric, aiming to deliver low-latency, high-throughput connectivity suitable for large-scale AI workloads, while also simplifying deployment and management complexities associated with Rail architectures.
Related content for AI networking infrastructure
DriveNets AI Networking Solution
Latest Resources on AI Networking: Videos, White Papers, etc
Recent AI Networking blog posts from DriveNets AI networking infrastructure experts
White Paper
Fabric-scheduled Ethernet as an effective backend interconnect for large AI compute clusters