



|
Getting your Trinity Audio player ready...
|
Then, something changed. I had gotten used to their daily calls, but suddenly they stopped. At first, I was proud — maybe my kids had finally learned to balance their screen time. But I also noticed they were visiting their grandfather, who lives nearby, more often. After a little investigation, I realized they had figured out a loophole: once their time was up at home, they could simply go to their grandfather’s house and use his phone without any limits — plus, they got candy in the process! 😊 My kids, like a new and growing market segment called NeoClouds, understand that resource shortage in one place can be overcome by tapping into resources in another.
NeoClouds and Their Challenges
NeoClouds, or GPU-as-a-service cloud providers, have grown significantly over the past two years, building large-scale data centers with thousands of GPUs. However, their rapid expansion has also highlighted two key challenges that all NeoCloud providers must tackle:
- Limited power resources: Large data centers consume vast amounts of power and space, especially those packed with GPUs. As the demand for compute power continues to rise, power and space constraints are becoming critical challenges.
- Global presence with AI-grade performance: Cloud providers inherently serve large-scale regions, and customers are often unaware of the specific locations of their resources. A single service may use resources from two different sites, meaning that, from a network perspective, the GPUs in these two locations must function as a single workload. For NeoCloud’s AI-driven applications, the crucial challenge isn’t just interconnecting workloads across distributed data centers but maintaining lossless connectivity. AI workloads require high-performance networking with lossless, predictable connections between GPUs. While this is relatively straightforward when GPUs are housed in the same data center, it becomes much more complex when data centers are, for example, 80 kilometers apart.
The ability to seamlessly share and optimize power resources across multiple locations — without sacrificing performance — is crucial for NeoClouds as they navigate these challenges. The right networking and infrastructure solutions will determine whether they can continue scaling effectively while maintaining the high-performance standards required by AI workloads.
Why Deep Buffers are Critical for Lossless DCI
Interconnecting data centers is not new — DCI (data center interconnect) has long been a standard solution in the cloud environment. What is new, however, is the challenge of delivering AI-grade performance. This means ensuring not just bandwidth, but also predictable low latency, minimal jitter, and, most critically, lossless packet delivery. Even minor packet loss can significantly impact AI training and inference accuracy.
This is where the combination of ECN (Explicit Congestion Notification) and PFC (Priority-based Flow Control) becomes essential. PFC acts as a last resort, a direct form of flow control that engages when congestion has already occurred. It prevents further degradation by sending a pause frame to the sender, instructing it to temporarily halt transmission. However, since PFC only activates after congestion has already set in, a more proactive approach is needed. This is where ECN plays a vital role — it provides an early warning of congestion by signaling to sending hosts to reduce their transmission rates before packet loss happens.
For ECN to function optimally, it must be paired with hardware deep buffers. Without sufficient buffer capacity, ECN propagation time is inadequate, leading to packet loss and degraded performance. Deep buffers provide ECN with the time it needs to manage congestion effectively, ensuring the desired lossless connectivity.
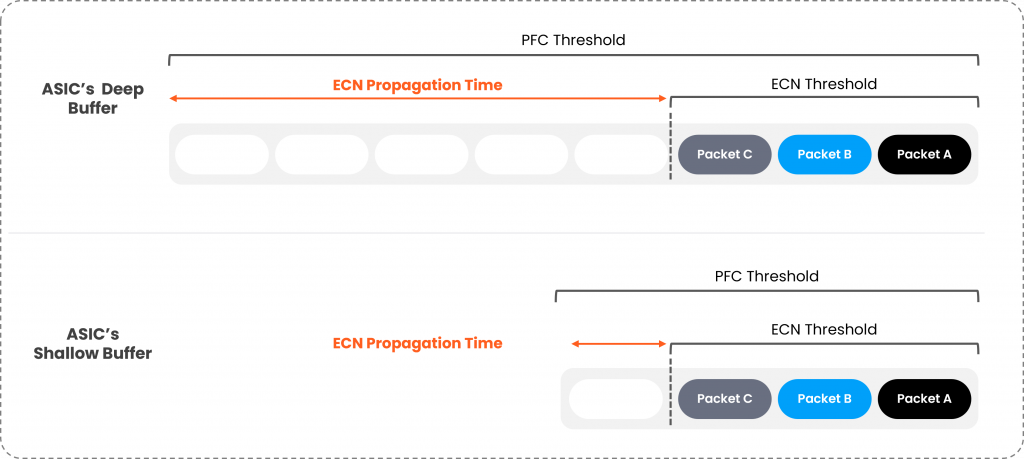 Deep buffer white boxes vs. shallow buffer white boxes
Deep buffer white boxes vs. shallow buffer white boxes
Distributed AI Workload Performance with DriveNets
Building on this, NeoCloud providers looking to distribute AI workloads across multiple remote data centers must establish a networking infrastructure that incorporates deep buffers. This ensures lossless connectivity and predictable performance, even when GPU clusters are distributed across significant distances.
DriveNets AI Fabric offers a fabric-scheduled Ethernet solution that delivers the fastest job completion time (JCT) performance, even outperforming NVIDIA’s known solutions. Within its cluster network, it supports both shallow and deep buffer Jericho3-AI. This allows AI workload builders to utilize shallow buffer white boxes for intra-data center GPU interconnects, while leveraging deep buffer white boxes for linking AI clusters across distributed data centers. This ensures seamless, lossless connectivity for large-scale AI workloads, even across distances of 10 km, 50 km, or 80 km.
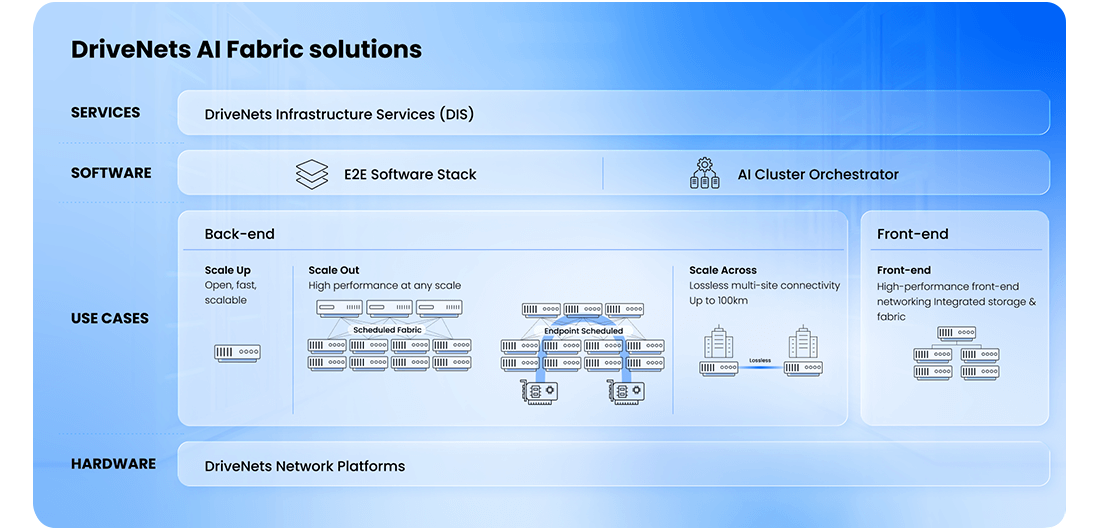 Interconnecting AI workloads with DriveNets AI Fabric
Interconnecting AI workloads with DriveNets AI Fabric
Distributing large-scale AI workloads without compromising performance
NeoClouds and even enterprises are pursuing the interconnection of AI clusters across multiple sites. This strategic move directly addresses the power and space constraints troubling specific sites. By distributing large-scale AI workloads, they can tap into their full potential of available power and space resources.
However, achieving this without compromising performance is not an easy task. DriveNets AI Fabric rises to this challenge, providing a fabric-scheduled Ethernet solution with deep buffer capabilities. This ensures that the highest levels of performance are maintained across interconnected GPUs, even when separated by distances of up to 80 km.
And, just like my twins, there’s a sweet treat in the process. For my kids, it’s the irresistible Hershey Kisses; for NeoClouds, it’s the integration of open, standard Ethernet from end to end.
Key Takeaways
- Resource Constraints: NeoCloud providers are interconnecting AI clusters across multiple sites to overcome power and space limitations at individual locations.
- Ensuring Lossless Connectivity: Maintaining high-performance, lossless connectivity between GPUs across distributed data centers is crucial for effective AI workload distribution.
- Optimizing Resource Utilization: By distributing AI workloads over interconnected sites, organizations can better utilize available power and space resources without compromising performance.
- DriveNets AI Fabric Solution: Offers a fabric-scheduled Ethernet architecture with deep buffer capabilities, enabling seamless, lossless connectivity for large-scale AI workloads across distances up to 80 km.
Additional Neocloud GPU-as-a-Service (GPUaaS) Infrastructure Resources
- NeoCloud Case Study: Highest-Performance Unified Fabric for Compute, Storage and Edge
- Scaling AI Workloads Over Multiple Sites through Lossless Connectivity
- Meeting the Challenges of the AI-Enabled Data Center: Reduce Job Completion Time in AI Clusters
- How is DriveNets revolutionizing network infrastructure for AI and service providers?
- Why InfiniBand Falls Short of Ethernet for AI Networking
- Fastest AI Cluster Deployment Now a New Industry Requirement
- CloudNets-AI – Performance at Scale
White Paper
Fabric-Scheduled Ethernet as an Effective Backend Interconnect for Large AI Compute Clusters