



|
Getting your Trinity Audio player ready...
|
What is a Network Bottleneck?
A network bottleneck is a condition where the flow of data is delayed due to limited computer resources, and typically occurs when bandwidth can not support the volume of data relayed at the speed at which it should be received.
Dial-up Network Bottlenecks
It was the case back in the dial-up modem days and then in the 2G and early 3G days. Any multimedia application, be it video conference, streaming or online gaming with advanced graphics, was limited to a local or campus network. That’s because remote connectivity (specifically WAN and access) either made those apps impossible or created a very poor quality of experience.
But that’s ancient history. Since then, xDSL, FTTX, 4G, 5G and other technologies have removed main networking bottlenecks. It has led to huge advancements in the application world as well as the rise of over-the-top (OTT) and cloud-based applications that essentially deleted the line between LAN and WAN.

Today’s Network Bottlenecks
These days, most application usage is agnostic to location or content. So, when you work on a document, watch a movie, or play a game, the user experience is the same – whether the file is stored locally or on a shared drive, or whether you watch a streamed 4K movie or one stored on your laptop.
So other than just being nostalgic, why are we talking about networks in the context of bottlenecks?
It turns out that networking’s progress created use cases in which such advancement is simply not enough, thereby making the network a bottleneck once again.
It sounds counterintuitive, but think about the parallel computing use case.
High-performance computing (HPC)
Parallel, high-performance computing is a field in which the differentiation between internal I/O mechanisms (e.g., PCIe) and the external I/O mechanism (e.g.,. Ethernet) is blurred, much like the blurring lines of WAN and LAN. In parallel computing, the connectivity between multiple compute devices (e.g. CPUs, GPUs) is run over an intra-server bus or an intra-cluster network. This is possible only because networking infrastructure can now reach the same rates and performance of the internal I/O bus.
This is great news for anyone who wishes to run large-scale compute tasks.
There is an issue, however.
The Compute-Bandwidth Gap
As noted, networks are turning into the bottlenecks in large-scale compute tasks, with external and internal I/O mechanisms becoming interchangeable as they offer (roughly) the same bandwidth. Take, for instance, PCIe 5.0; it supports 128GB/s (1024Gbps) while Ethernet supports 800Gbps, which are in the same ballpark.
This interchangeability enabled the growth of parallel computing, in which a large number of compute elements (mainly GPUs) work, in parallel, on the same computational job. This cluster of servers is, basically, a very large computer (or, a supercomputer). The intra-server I/O protocols (such as PCIe and NVLink) and inter-server I/O protocols (such as Ethernet and InfiniBand) take a similar and equally important part in this.
It turns out, however, that there is a new gap that develops in this architecture, as described by Meta’s VP of Engineering, Infrastructure, Alexis Bjorlin, in her keynote session last year at the 2022 OCP Global Summit.
This new growing gap is between compute capabilities/capacity (in FLOPS) and the bandwidth of memory access and interconnect, as shown in the timeline graph below.
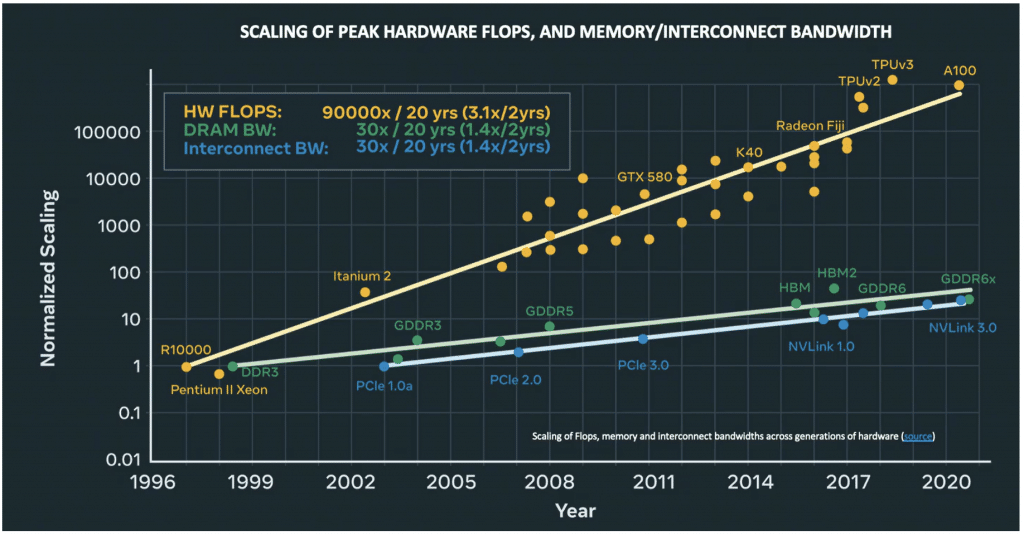
This gap makes the network, yet once again, a bottleneck.
This bottleneck becomes acute in systems in which the compute process is heavily dependent on the inter-server, or inter-GPU, connectivity. This is the case in AI clusters, especially in large-scale ones, in which this networking performance lag causes GPU idle cycles.
In this case, the phenomenal HW FLOPS growth is degraded by networking. If you have an extremely powerful GPU, it is a shame to see it idle for up to 50% of the time as it awaits information from another GPU in the same cluster. This delay is due to latency, jitter or packet drops in the interconnecting network.
As mentioned, this is extremely important in AI cluster networking. Fortunately, there are several solutions that can somehow ease this pain, some of which are more suitable than others.
Resolving AI Back-End Network Bottlenecks with Network Cloud-AI
The network as a bottleneck that slows down applications and prevents new use cases (and business) from becoming feasible seems like a very old notion. These days, most application usage is agnostic to location or content. So, when you work on a document, watch a movie, or play a game, the user experience is the same – whether the file is stored locally or on a shared drive, or whether you watch a streamed 4K movie or one stored on your laptop. It turns out that networking’s progress created use cases in which such advancement is simply not enough, thereby making the network a bottleneck once again.
Related content for AI networking architecture
DriveNets AI Networking Solution
Latest Resources on AI Networking: Videos, White Papers, etc
Recent AI Networking blog posts from DriveNets AI networking infrastructure experts
As mentioned, the challenges facing AI back-end networks come from some unique requirements derived from its: huge scale (1000s of 400/800Gbps ports in a single cluster), online nature (that benefits from the same technology at the front end and the back end), goal of optimizing its compute (GPU) resources and yielding fastest JCT (job completion time) performance.
If we try to categorize those requirements, according to which we can evaluate different solutions, the following three categories emerge as essential:
Architectural flexibility
- Multiple and diverse applications
- Support of growth
- Web connectivity (unlike isolated HPC)
High performance at scale
- Support of growth
- Huge-scale GPU deployment larger than chassis limit
- Fastest JCT via
- Resilience
- High availability
- Minimal blast radius, etc.
- Predictable lossless, low-latency and low-jitter connectivity – reducing GPU idle cycles
Trusted ecosystem
- Standard interfaces allowing multi-vendor mix-and-match – avoiding HW/ASIC vendor lock
- Field-proven interconnect solutions – reducing risk
Industry solutions for AI Networking and their drawbacks
There are several notable industry solutions for AI back-end networking:
Non-Ethernet (e.g., Nvidia’s InfiniBand)
This semi-proprietary, non-Ethernet solution provides excellent performance as a lossless, predictable architecture, which leads to adequate JCT performance. On the other hand, it practically leads to a vendor lock, both on the networking level and on the GPU level. It also lacks the flexibility to promptly tune to different applications, requires a unique skill set to operate, and creates an isolated design that cannot be used in the adjacent front-end network.
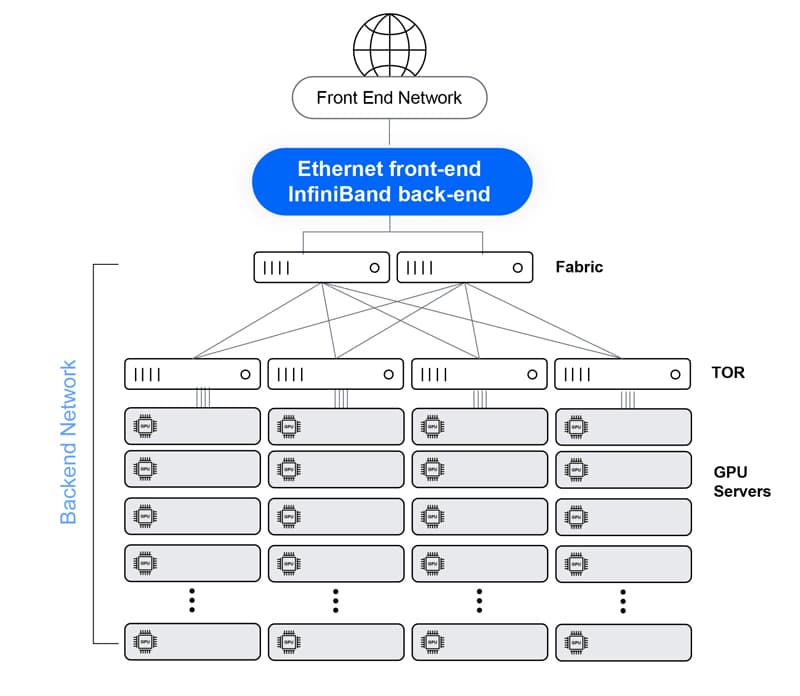
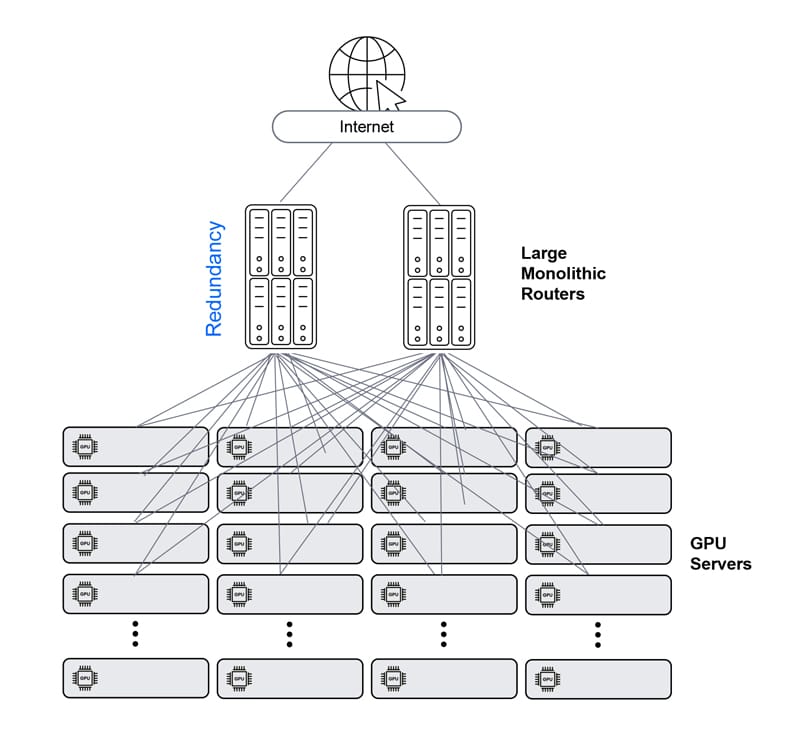
Ethernet – Clos architecture
Ethernet is the de facto standard in networking, which makes it very easy to plan and deploy. When built in a Clos architecture (with Tor leaves and chassis-based spines), it is practically unlimited in size. On the other hand, its performance degrades as the scale grows, and its inherent latency, jitter and packet loss cause GPU idle cycles and reduce JCT performance. It is also complex to manage in high scale, as each node (leaf or spine) is managed separately.
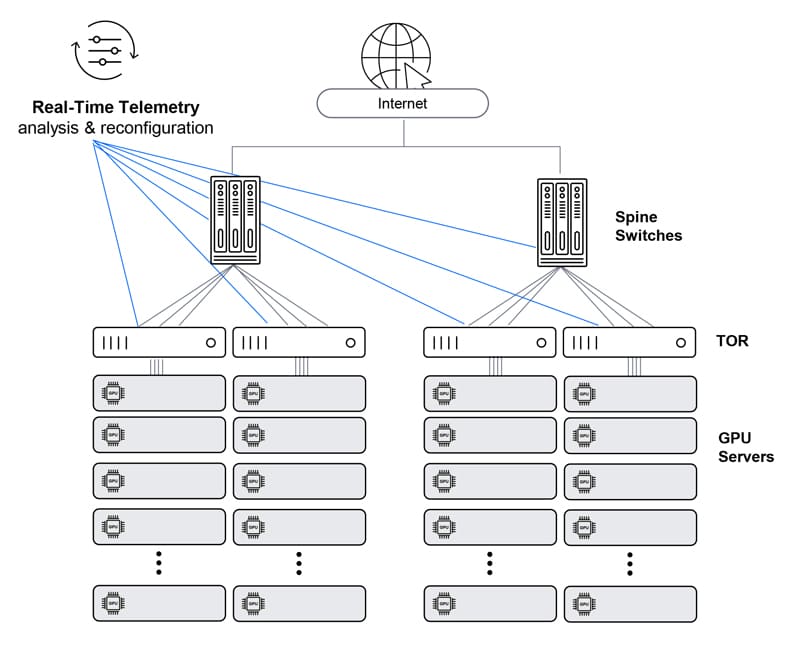
Ethernet – Clos architecture with enhanced telemetry
Enhanced telemetry can somewhat improve Clos-architecture Ethernet solution performance via monitoring buffer/performance status across the network and proactively policing traffic. Having said that, such a solution still lacks the performance required for a large-scale AI network.
Ethernet – single chassis
A chassis resolves the inherent performance issues and complexity of the multi-hop Clos architecture, as it reduces the number of Ethernet hops from any GPU to any GPU to one. However, it cannot scale as required, and also poses a complex cabling management challenge.
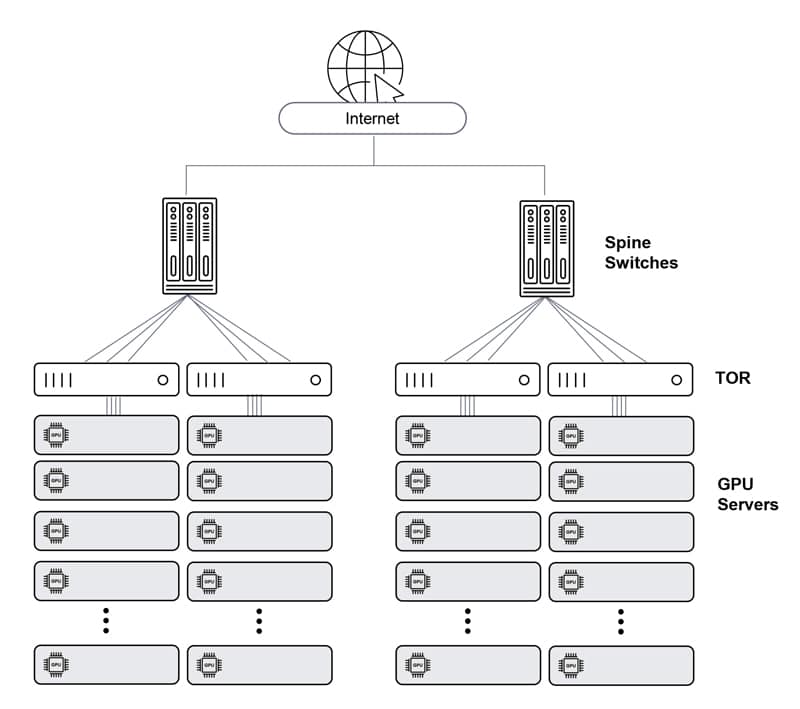
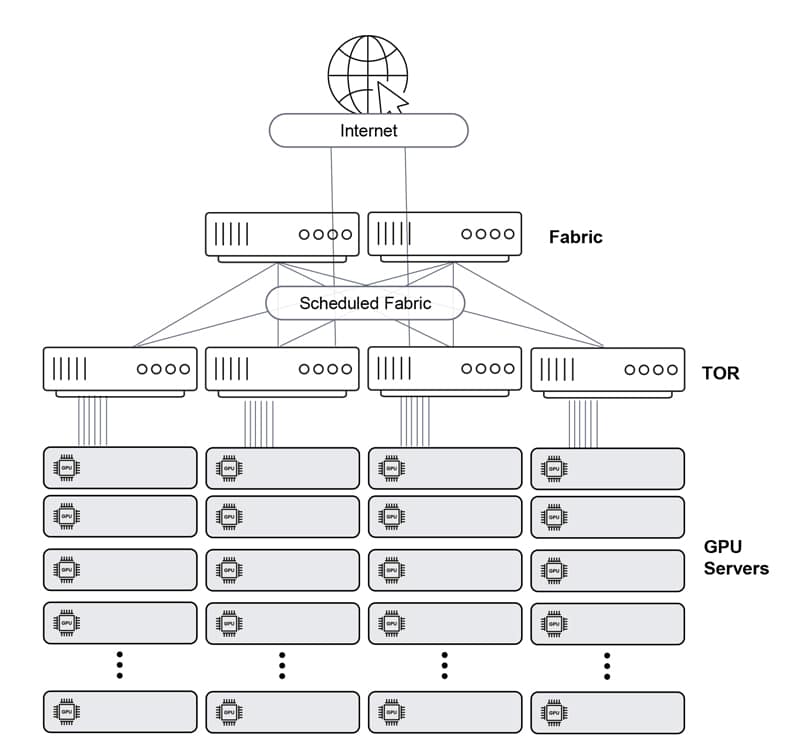
Ethernet – Distributed Disaggregated Chassis (DDC)
Finally, the DDC solution offers the best of all worlds. It creates a single-Ethernet-hop architecture that is non-proprietary, flexible and scalable (up to 32,000 ports of 800Gbps). This yields workload JCT efficiency, as it provides lossless network performance while maintaining the easy-to-build Clos physical architecture. In this architecture, the leaves and spine are all the same Ethernet entity, and the fabric connectivity between them is cell-based, scheduled and guaranteed.
DDC solution: the best fit for AI networking requirements
The following table summarizes the different solutions above according to the categories defined earlier:

It is easy to see that the DDC solution is the best fit for AI networking requirements. While there are several vendors that claim to have a DDC-based solution, DriveNets Network Cloud-AI is the only one that is available and field-proven.
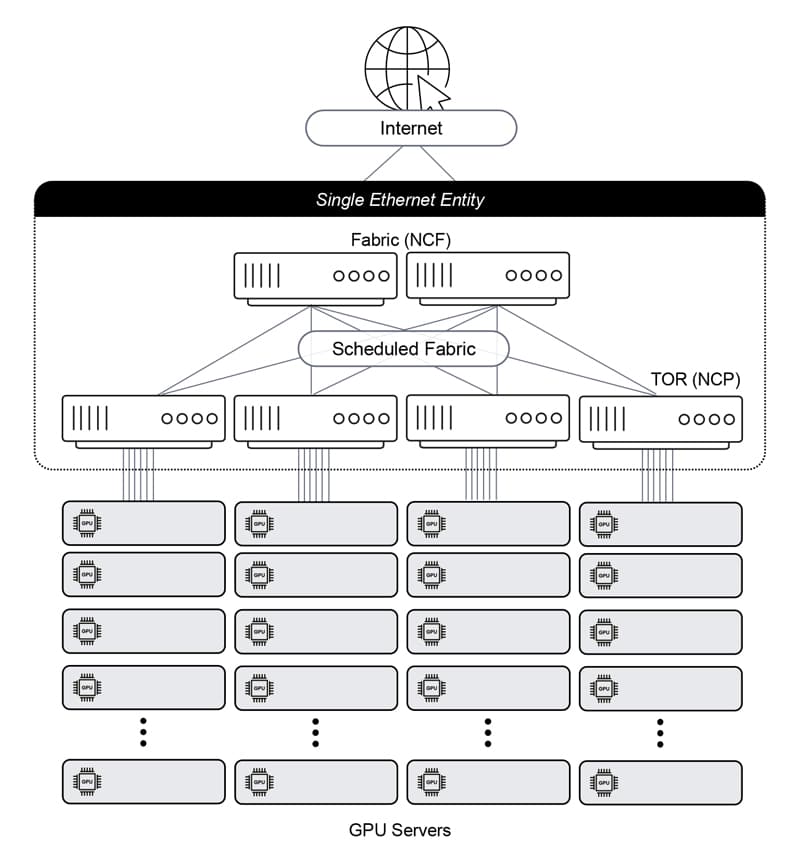
DriveNets Network Cloud-AI is the most innovative networking solution available today for AI. It maximizes the utilization of the AI infrastructures and substantially lowers their cost, in a standard-based implementation that doesn’t give up vendor interoperability.
The Highest-Performance Ethernet AI Fabric
With the fast growth of AI workloads and infrastructures buildups, network solutions used in the fabric of AI clusters need to evolve to maximize the utilization of costly AI resources (AI accelerators, GPUs, etc.) and support standard connectivity that enables vendor interoperability. AI Training clusters need networking fabric that provides lossless, predictable connectivity.
Maximizing the utilization of AI infrastructures and substantially lowering their costs, DriveNets Network Cloud-AI is based on the largest-scale Distributed Disaggregated Chassis (DDC) architectures in the world. In recent trials by hyperscalers, it demonstrated the delivery of lossless connectivity and 10%-30% improvement in JCT (Job Completion Time) of highscale, high-performance AI workloads. This makes DriveNets Network Cloud-AI the most cost-effective Ethernet solution for AI infrastructures that effectively “pays for itself” by maximizing the utilization of AI resources, in a standard-based implementation that doesn’t give up vendor interoperability.
DriveNets Network Cloud-AI will come to set networking standards for high-performance AI workloads, providing the highest-performance Ethernet solution for AI networking.
Download White Paper
Utilizing Distributed Disaggregated Chassis (DDC) for Back-End AI Networking Fabric