

What is AI Networking? Building Networks for AI Workloads
AI Networking Overview
With the exponential growth of AI workloads as well as distributed AI processing traffic placing massive demands on network traffic, network infrastructure is being pushed to their limits. AI infrastructure buildups need to support large and complex workloads running over individual compute and storage nodes that work together as a logical cluster. AI networking connects these large workloads via a high-capacity interconnect fabric. HPC/AI workloads are applications that run over an array of high performance compute (HPC) servers. Those servers typically host a dedicated computation engine like a GPU/FPGA/accelerator, in addition to a high performance CPU, which by itself can act as a compute engine, and some storage capacity, typically a high-speed SSD. The HPC/AI application running on such servers do not run on a specific server, but on multiple servers simultaneously, ranging from a few servers or even a single machine to thousands of machines all operating in synch and running the same application – distributed amongst them. The interconnect (networking) between these computation machines needs to allow “any to any” connectivity between all machines running the same application, as well as cater to different traffic patterns, associated with the type of application running as well as stages of the application’s run.The AI Networking Market
The AI market is gaining momentum, with businesses of all sizes investing in AI-powered solutions. According to IDC investment in AI infrastructure buildups will reach $154B in 2023, growing to $300B by 2026. In 2022, the AI networking market had reached $2B, with InfiniBand responsible for 75% of that revenue.AI clusters need to evolve
A data center has servers with CPUs and GPUs, each connecting to a leaf or top of rack switch that connects to a centralized or spine chassis-based switch and ultimately connects to the Internet, where most of the queries come from, so not a lot of backend traffic. This Clos architecture is the best one for data centers. AI clusters are supercomputers built to perform complex, large-scale AI jobs, and are composed of thousands of processing units (predominantly GPUs). Computer workloads run in parallel on multiple GPUs, and need to be highly utilized. This poses significant challenges to the AI networking infrastructure, which needs to support thousands of high-speed ports (400 and 800 Gbps). To support that, these servers need backend communications between them, generating high volumes of east west traffic. Since one workload runs on multiple servers, high bandwidth, no jitter and no packet loss are a requirement in order to ensure the highest GPI utilization. Any degradation in network performance will impact the Job Completion Time (JCT). With the fast growth of AI workloads, network solutions used in the fabric of AI clusters need to evolve to maximize the utilization of costly AI resources and support standard connectivity that enables vendor interoperability.What are the networking requirements of HPC/AI workloads?
When trying to address the additional complexity imposed by the HPC/AI workloads, the solution used in hyperscale data centers falls short. Artificial intelligence (AI) workloads often require special network infrastructure. The networking requirements for hyperscale data centers include:- Huge scale – 1000s of 100G-800G ports in a single cluster (beyond chassis limit)
- Optimal utilization of AI accelerators (GPUs) – predictable lossless connectivity
- Fastest JCT (job completion time) – highest performance and predictable, reliable connectivity
- Network Interoperability – avoid of vendor lock (Ethernet) and support variety of white boxes, NOCs and AI ASICs
What are the attributes that make AI networking unique?
Networks are built to run AI workloads different than regular data center networks. While hyperscale, cloud resident data centers and HPC/AI clusters have a lot of similarities between them, the solution used in hyperscale data centers falls short for addressing the additional complexity imposed by HPC/AI workloads. Here are some examples of the attributes faced in an AI networking space:- Parallel computing – AI workloads are a unified infrastructure of multiple machines running the same application and same computation task
- Size – size of such task can reach thousands of compute engines (e.g., GPU, CPU, FPGA, Etc.)
- Job types – different tasks vary in their size, duration of the run, the size and number of data sets it needs to consider, type of answer it needs to generate, etc. this as well as the different language used to code the application and the type of hardware it runs on contributes to a growing variance of traffic patterns within a network built for running AI workloads
- Latency & Jitter – some AI workloads are resulting a response which is anticipated by a user. The job completion time is a key factor for user experience in such cases which makes AI latency an important factor. However, since such parallel workloads run over multiple machines, the latency is dictated by the slowest machine to respond. This means that while latency is important, jitter (or latency variation) is in fact as much a contributor to achieve the required job completion time
- Lossless – following on the previous point, a response arriving late is delaying the entire application. Whereas in a traditional data center, a message dropped will result in retransmission (which is often not even noticed), in an AI workload, a dropped message means that the entire computation is either wrong or stuck. It is for this reason that AI running networks requires lossless behavior of the network. IP networks are lossy by nature so for an IP network to behave as lossless, certain additions need to be applied. This will be discussed in. follow up to this paper.
- Bandwidth – large data sets are large. High bandwidth of traffic needs to run in and out of servers for the application to feed on. AI or other high performance computing functions are reaching interface speeds of 400Gbps per every compute engine in modern deployments.
What are requirements for an AI networking solution?
An interconnect solution for HPC/AI is different from a network built to serve connectivity to residential households or a mobile network as well as different than a network built to serve an array of servers purposed to answers queries from multiple users as a typical data center structure would be used for. The infrastructure must insure, via predictable and lossless communication, optimal GPU performance (minimized idle cycles awaiting network resources) and maximized JCT performance. This infrastructure also needs to be interoperableand based on an open architecture to avoid vendor lock (for networking or GPUs). A networking solution serving HPC/AI workloads will need to carry certain attributes:Architectural flexibility
- Multiple and diverse applications
- Support of growth
- Web connectivity (unlike isolated HPC)
High performance at scale
- Support of growth
- Huge-scale GPU deployment larger than chassis limit
- Fastest JCT via (Resilience, high availability, minimal blast radius, etc., Predictable, lossless, low-latency and low-jitter connectivity – reducing GPU idle cycles)
Trusted ecosystem
- Standard interfaces allowing multi-vendor mix-and-match – avoiding HW/ASIC vendor lock
- Field-proven interconnect solutions – reducing risk
Industry solutions for AI networking
There are a number of notable industry solutions for AI back-end networking.Non-Ethernet (e.g., Nvidia’s InfiniBand)
InfiniBand provides excellent performance as a lossless, predictable architecture, leading to adequate JCT performance. It lacks the flexibility to promptly tune to different applications, requires a unique skillset to operate, and creates an isolated design that cannot be used in the adjacent front-end network.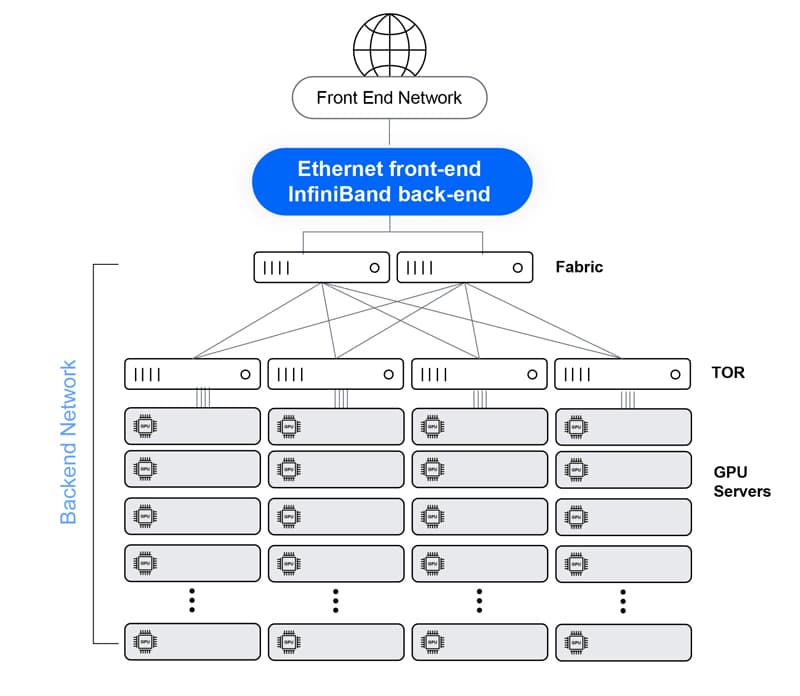
Ethernet – Clos architecture
Very easy to plan and deploy. When built in a Clos architecture (with Tor leaves and chassis-based spines), it is practically unlimited in size. However, performance degrades as the scale grows, and its inherent latency, jitter and packet loss cause GPU idle cycles, reducing JCT performance. It is also complex to manage in high scale, as each node (leaf or spine) is managed separately.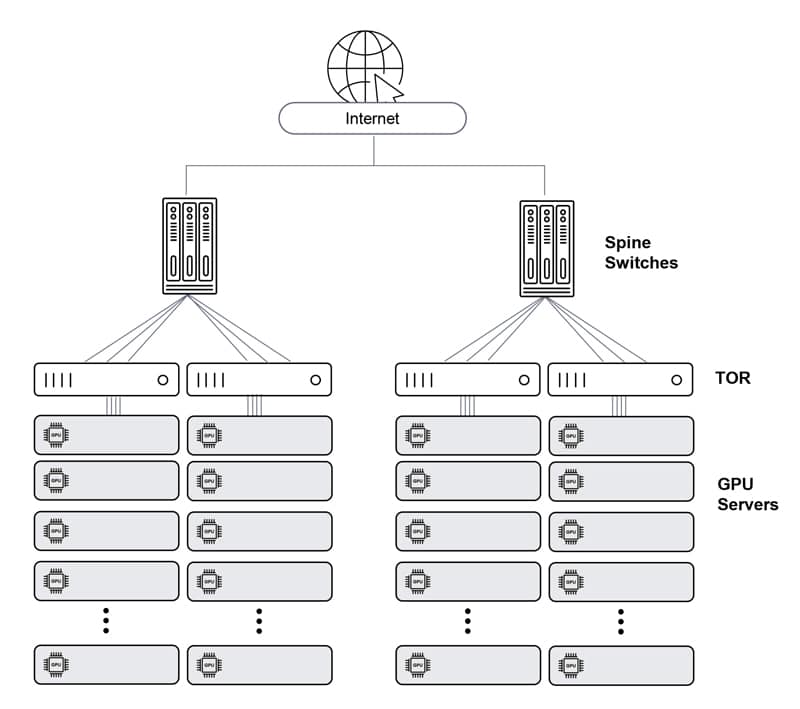
Ethernet – Clos architecture with enhanced telemetry
Somewhat improves Clos-architecture Ethernet solution performance via monitoring buffer/performance status across the network and proactively polices traffic. Yet, still lacks the performance required for a large-scale AI network.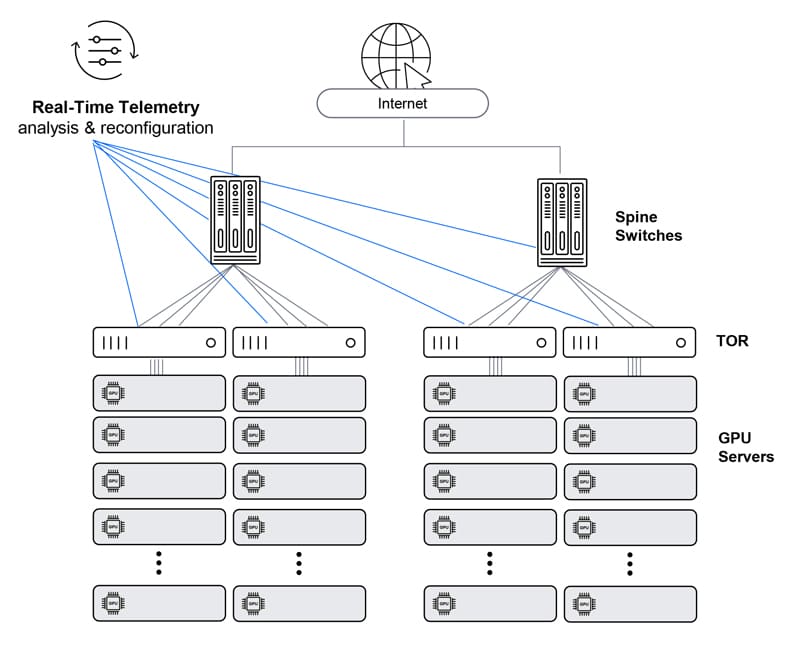
Ethernet – single chassis
resolves the inherent performance issues and complexity of the multi-hop Clos architecture, reducing the number of Ethernet hops from any GPU to any GPU to one. But, it cannot scale as required, and also poses a complex cabling management challenge.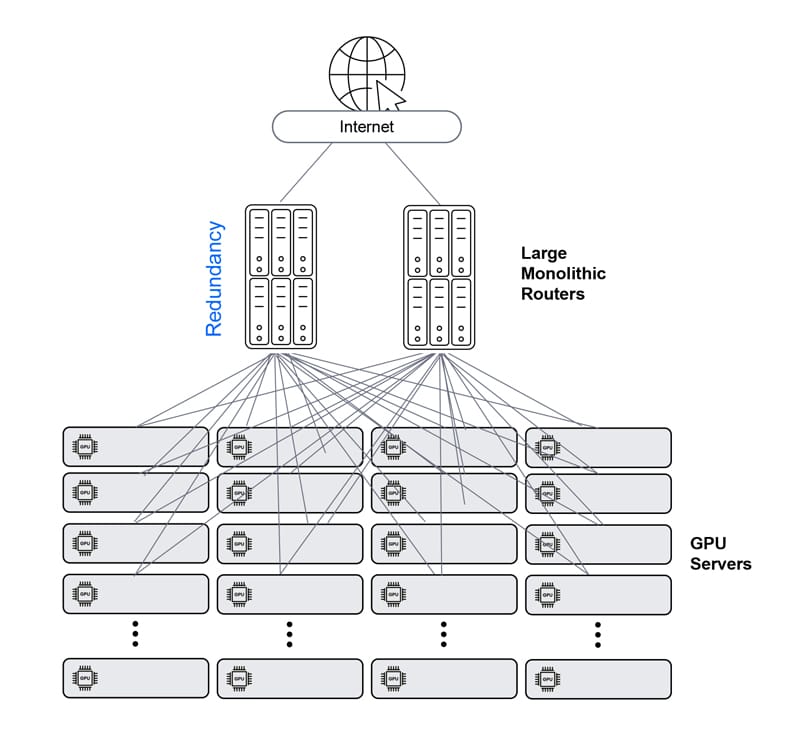
Fabric Scheduled Ethernet
DriveNets’ scheduled fabric technology minimizes congestion and jitter, providing predictable connectivity with consistent low latency and nanosecond failover recovery. The platform’s end-to-end virtual output queueing (VOQ) offers inherent traffic isolation, effectively mitigating multi-tenancy issues like the “noisy neighbor” effect. Ethernet solution for AI networking. A distributed fabric solution presents a standard solution that matches the forecasted industry need both in terms of scale and in terms of performance.DriveNets AI Fabric
DriveNets hardware platforms are designed and optimized for the diverse requirements of AI fabrics. These Ethernet-based switching platforms support both front-end and back-end use cases and include both Fabric-Scheduled Ethernet (FSE) and Endpoint-Scheduled Ethernet (ESE) architectures. The platforms support speeds of up to 1.6 Tbps and are open to work with any optics and GPU vendor. DriveNets’ Fabric-Scheduled Ethernet delivers industry-leading performance for AI/HPC backends, while maintaining the cost-efficiency and openness of standard Ethernet.- +72% Better performance vs traditional Ethernet
- +15% Better performance vs SpectrumX
- +6% Better performance vs InfiniBand
Frequently Asked Questions
Why do AI networks require lossless communication behavior?
AI networking requires absolute lossless behavior because a single dropped message can cause the entire distributed computation to stall or produce incorrect results. Unlike traditional data center networks that rely on standard packet retransmission, AI infrastructure must eliminate dropped packets to minimize GPU idle cycles and maximize total Job Completion Time performance.
What is the scale and performance capacity of a Distributed Disaggregated Chassis architecture for AI?
The Distributed Disaggregated Chassis architecture scales up to 32,000 ports of 800Gbps to support massive GPU clusters. This innovative design implements a single-Ethernet-hop fabric that provides non-proprietary, flexible, and completely lossless network performance, effectively optimizing Job Completion Time while maintaining a standard, easily managed physical Clos architecture.
How do AI networking infrastructures maximize GPU utilization across large-scale clusters?
AI networking infrastructures maximize GPU utilization by providing predictable, low-latency, and low-jitter connectivity across thousands of interconnected processing nodes. By ensuring a lossless fabric, the system successfully eliminates idle cycles where accelerators wait for network resources, thereby securing the fastest Job Completion Time for complex parallel computing workloads.
Additional AI Networking Resources
AI Networking Solution Press releases- The Highest-Performance Ethernet Solution for AI Networking
- DriveNets Joins Ultra Ethernet Consortium; Commits to Developing Open, Multi-vendor Ethernet Solutions for AI
- DriveNets and Accton Technology Launch the Highest-Performance Ethernet-Based AI Networking Solution
- Forbes: With 52% Of AT&T’s Traffic, DriveNets Aims At AI Networking
- Silverlinings: DriveNets revamps Ethernet to connect AI megaclusters in the cloud
- 650 Group: DriveNets Enters the AI Networking, A Market Expected to Exceed
- Packet Pushers: Whitebox offering from Drivenets for building a data center fabric for AI workloads
- The Next Platform: You Don’t Have to Wait for Ultra Ethernet to Goose AI Performance
- Futurism: DriveNets Advances AI Networking
- 650 Group: Choosing InfiniBand or Ethernet? Ethernet-based AI Networking to grow at over 100% CAGR
- Utilizing Distributed Disaggregated Chassis (DDC) for Back-End AI Networking Fabric
- Meeting the Challenges of the AI-Enabled Data Center: Reduce Job Completion Time in AI Clusters
- Analysis of Data Traffic Distribution Solutions
- Scala Computing DriveNets Simulations External Report


