



|
Getting your Trinity Audio player ready...
|
The gap lies in software optimization. ROCm is a highly capable and actively developed stack, and the AMD ecosystem is rapidly maturing with strong momentum behind it. Cluster builders who go beyond standard out-of-the-box configurations and deploy targeted software enhancements can fully unlock the massive compute and memory potential that AMD hardware offers.
This blog showcases DriveNets’ journey of going beyond standard out-of-the-box configurations, diving deep into the all-reduce implementation to unlock the full potential of AMD hardware for distributed LLM inference.
Attention is all you need. All-Reduce is what scales it
To understand the All-Reduce bottleneck, we have to look at the mechanics of how Large Language Models (LLMs) process massive inputs. As users demand increasingly large context windows, such as analyzing a 64K token document (roughly a 200-page document), the underlying math becomes significantly more intensive. When the model handles this input during the attention phase, the resulting matrix multiplications become so large that they exceed the memory capacity of any single GPU.
To solve this, the workload must be distributed across multiple GPUs using the tensor parallelism technique. Because the mathematical calculation is split, the GPUs must coordinate closely. They must constantly synchronize their individual results to move forward. This global synchronization relies heavily on a specific collective communication operation known as all-reduce. All-reduce takes the disparate vectors from multiple GPUs, adds them together, and distributes the combined result back to everyone.
Standard RCCL libraries typically execute this all-reduce operation using classic linear ring or tree topologies. This can introduce a synchronization challenge at LLM inference scale. Because data transfers happen sequentially, GPUs must wait for information to pass through the network before they can begin the next calculation.
For the end user, this causes high latency and sluggish responses. Instead of getting fast answers, the system lags while the hardware struggles to coordinate, making the AI workload slower and more expensive to run.
Bypassing out-of-the-box all-reduce
To overcome this software limitation, our R&D built a custom implementation tailored directly for AMD Instinct GPUs, introducing a modified RCCL implementation for the MI355X that enhances the standard all-reduce operations with versions optimized for the LLM interconnect requirements.
Instead of treating the standard all-reduce flow as a fixed constraint, we analyzed where communication overheads were introduced and restructured parts of the process based on a more efficient hierarchical approach, inspired by recent academic research and adapted into the DriveNets and AMD communication stack.
At a high level, this keeps most data movement local and allows GPUs to exchange data across nodes at the same time instead of waiting in sequence, reducing delays and removing the step-by-step bottlenecks of traditional all-reduce.
Slashing the time to first token (TTFT)
In modern LLM deployments, meeting strict Service Level Agreements requires consistent performance even when utilizing large context windows. Many of our customers require a challenging TTFT upper limit for growing context window sizes, which is a target unattainable with standard software stacks. This limitation often forces engineers to throttle concurrency to a very low number of simultaneous requests just to maintain acceptable latency. This is exactly where we implemented a hierarchical software enhancement optimized for the prefill stage of LLM processing. To demonstrate the impact, we conducted a series of benchmark tests on AMD Instinct workloads targeting message sizes common in LLM inference workloads. By specifically optimizing the prefill stage for data sizes ranging from 128KB up to 8MB, this enhancement is incredibly effective.
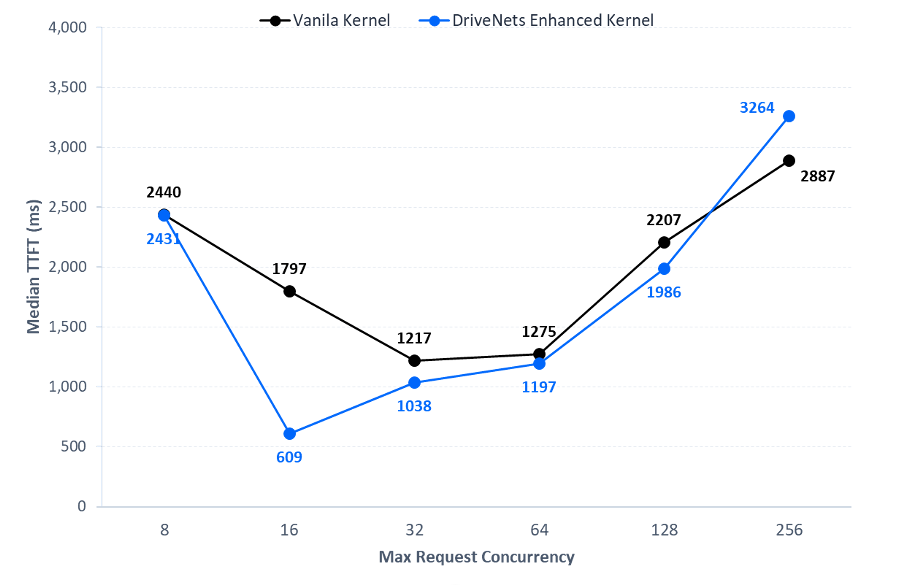
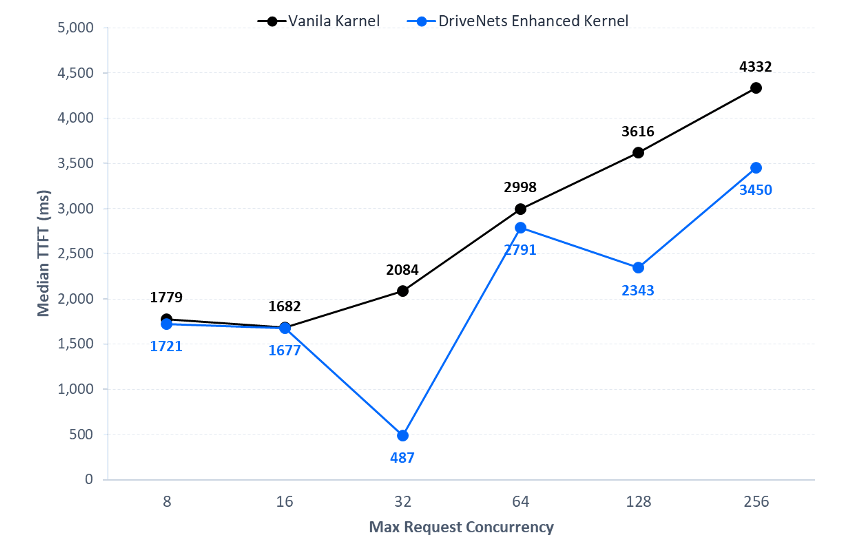
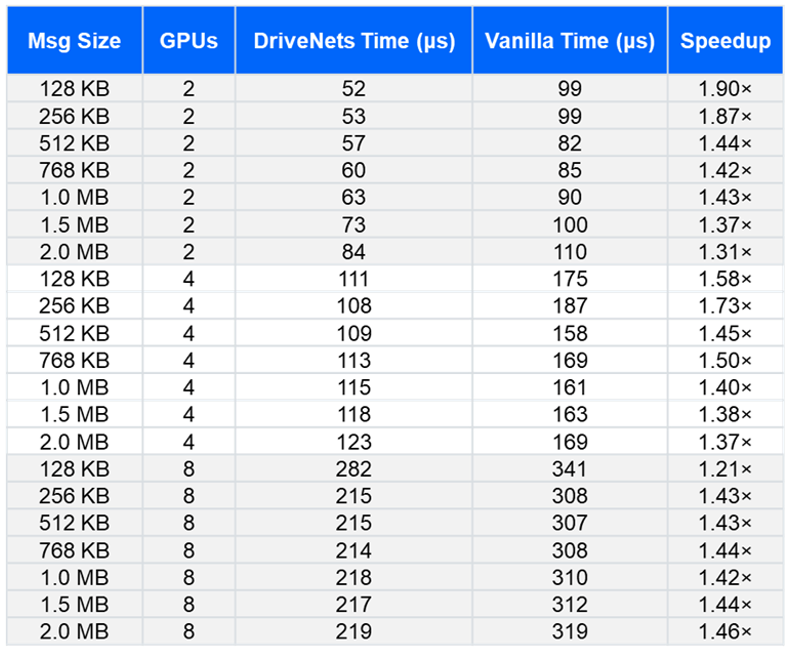
Key results:
- Raw hardware-level testing shows improved latency across the typical message sizes used in LLM inference workloads
- Up to 4.3x improved latency when testing a 1K input / 8K output configuration
- Up to 3x improved latency when testing an 8K input / 1K output configuration
Maximizing your AMD investment
Ultimately, AI cluster builders are right to embrace AMD hardware. The massive memory and compute density offer significant advantages, but peak performance requires more than promising specifications. It demands a deep understanding of how the customer’s inference workload works and the ability to optimize the entire workload stack to unlock the hardware’s full potential.
This is where the DriveNets Full-Stack approach provides value. We deliver a bottom-up tuning process that covers the complete software stack, from inference framework configuration and deep-stack optimization through validation and production operations.
The custom all-reduce implementation detailed in this blog is one example of that philosophy. We identify exactly where the software stack constrains the hardware for a specific use case and re-engineer that layer with precision, leveraging AMD-specific capabilities such as Infinity Fabric interconnect topology and ROCm-native kernel tuning. By doing so, DriveNets AI Fabric eliminates network bottlenecks and ensures the compute investment is never held back by the software surrounding it.
Key Takeaways
- Software optimization is essential for AMD hardware
While AMD Instinct GPUs provide significant hardware advantages in memory capacity and compute density , cluster builders must move beyond “out-of-the-box” configurations and implement targeted software enhancements to fully unlock that potential. - Custom all-reduce implementations solve latency bottlenecks
Standard communication libraries often introduce synchronization challenges during LLM inference. By utilizing a custom, hierarchical all-reduce approach tailored for AMD interconnects, DriveNets reduced communication overhead and removed sequential bottlenecks. - Significant performance gains are achievable
Through deep-stack optimization and raw hardware-level testing, the custom implementation achieved up to a 4.3x improvement in latency for specific 1K input/8K output configurations and a 3x improvement for 8K input/1K output configurations.
Frequently Asked Questions
Why is the standard all-reduce operation a bottleneck for LLM inference on AMD GPUs?
The all-reduce bottleneck occurs because standard libraries like RCCL often use linear ring or tree topologies that execute data transfers sequentially. As context windows grow to 64K tokens, workload distribution via tensor parallelism requires constant synchronization between GPUs. Sequential transfers force GPUs to wait, resulting in high latency and sluggish responses for end users.
How does DriveNets’ custom all-reduce implementation improve performance on AMD Instinct GPUs?
DriveNets improves performance by replacing standard sequential flows with a hierarchical approach tailored for the MI355X and Infinity Fabric interconnect. This optimized stack keeps most data movement local and enables simultaneous data exchange across nodes. By eliminating step-by-step bottlenecks, the implementation ensures that software constraints do not hold back the massive memory and compute density of AMD hardware.
What specific latency improvements does the DriveNets Full-Stack approach deliver for LLM workloads?
The DriveNets custom implementation delivers up to 4.3x improved latency when testing a 1K input / 8K output configuration on AMD Instinct GPUs. For workloads featuring an 8K input / 1K output configuration, raw hardware-level testing shows a 3x improvement in latency. These targeted software enhancements allow cluster builders to fully unlock the hardware’s potential across typical LLM inference message sizes.
Related content for AI networking infrastructure
DriveNets AI Networking Solution
Latest Resources on AI Networking: Videos, White Papers, etc
White Paper
Scaling AI Clusters Across Multi-Site Deployments