



|
Getting your Trinity Audio player ready...
|
Key AI networking infrastructure requirements
Building a large-scale cluster of GPUs with the highest performance in terms of job completion time (JCT)
This is based on:
- a networking fabric that provides high availability, low latency, minimal jitter, and a lossless environment – required to minimize GPU idle cycles in which they await networking resources while performing collective operations
- seamless recovery from failures that could make the difference between a minor latency rise and a job restart
- consistent-performance fabric at any scale and across different workloads, in terms of non-blocking bisection bandwidth, low latency, packet loss, etc.
Creating networking architecture flexibility and openness that enable operational and supply chain flexibility
This is based on:
- an open ecosystem that supports any GPUs and network interface controllers/cards (NICs), is workload-agnostic, and accommodates multiple applications and configurations
- standard-based (Ethernet) technology, as opposed to proprietary technology like InfiniBand that leads to vendor lock
- ultra scalability – supporting thousands of 400/800G ports in a single AI cluster
DDC – a scheduled fabric solution
Distributed Disaggregated Chassis, or DDC, is a scheduled Ethernet fabric solution that meets all the abovementioned requirements.
It is a scheduled fabric with the following advantages:
- Cell-based fabric that makes the entire cluster act as a single Ethernet node – supporting a single Ethernet hop from any GPU to any GPU, just like when connecting with a chassis, only at a much larger scale than possible in the confinement of a chassis
- Clos physical architecture – where the top-of-rack (ToR) switch is the Network Cloud Packet Forwarder (NCP) white box, while the fabric switch is the Network Cloud Fabric (NCF) white box
- Cell-spraying mechanism – running from ingress NCP to all NCFs and back to egress NCP, thus ensuring perfectly equal load balancing, no congestion, and no elephant flows
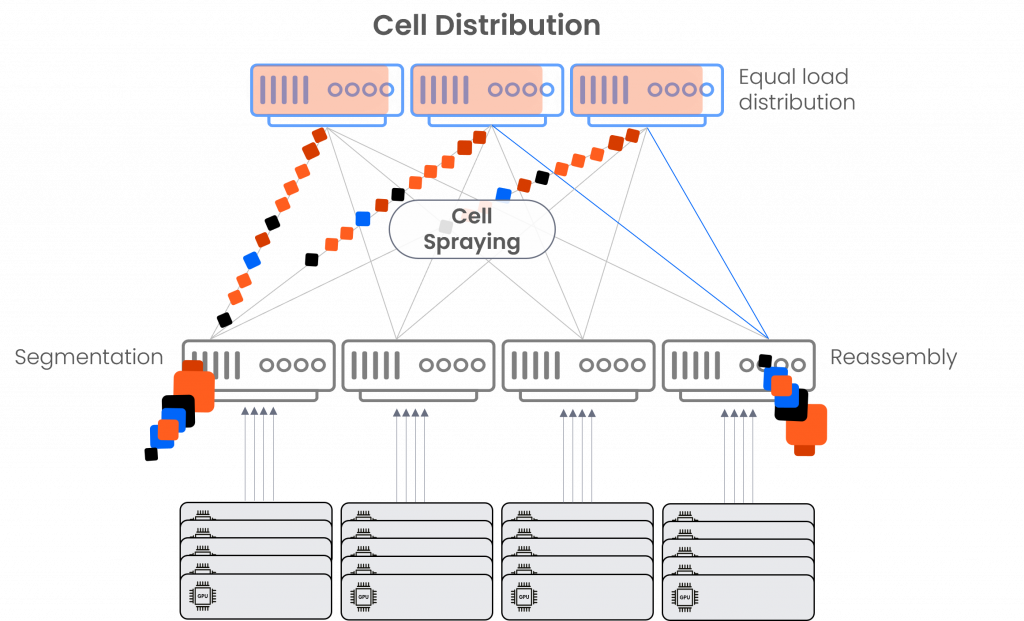
- No packet loss – with virtual output queueing (VOQ) per egress NCP at ingress NCP and grant-based flow control
- Supporting 32K GPUs (800Gbps) per cluster
- Lossless, predictable connectivity, low latency and practically zero jitter
- Nanosecond failover, no job reset
- No vendor lock – vendor agnostic GPUs, DPUs/NICs, ASICs, workloads
- Diverse AI application support – delivering high performance even when network requirements change
- Ethernet-based – ensuring interoperability and leveraging well-known protocol (Ethernet) for ease of build and operation
- Tested and field-proven solution – DriveNets Network Cloud already powers the world’s largest networks
The ByteDance journey
ByteDance has partnered with DriveNets and Broadcom to test a DDC scheduled fabric over the past several months with positive results. This motivated ByteDance to deploy the world’s first 1K GPGPU production cluster powered by DDC scheduled fabric in July 2024.
Configuration and scale
The computation cluster consists of 1,280 xPUs and 640 endpoints at a speed of 400GE. Built with a two-tier DDC, it forms a non-blocking domain for the whole cluster.
The leaf layer consists of 20 compact 2RU NCP white boxes, each powered by 2 Broadcom Jericho2C+ ASICs, providing 32 ports of 400GE to xPU and 40 ports of 400G to the spine. The spine layer includes 20 NCF white boxes in the same 2RU form factor, leveraging two Broadcom Ramon ASICs per box, offering a total of 48 ports of 400G per system.
NCP leaf nodes provide native over-provisioning. Each leaf connects with twenty spine NCFs, allowing for approximately 25% redundancy. The fabric can maintain nearly 100% throughput even with up to three NCF failures. Further failures impact performance linearly, based on ByteDance’s qualification results.
Distributed or centralized management
Scheduled fabric can be managed centrally or in a distributed manner. For centralized management, a controller (with a secondary one for 1+1 protection) orchestrates NCPs and NCFs, running protocols on dedicated servers. ByteDance chose a distributed approach based on the groundbreaking DriveNets Network Operating System (DNOS), similar to managing non-scheduled fabrics where each node runs protocols independently, with minimal operational changes. This approach seamlessly integrated with ByteDance’s existing orchestration system.
Power efficiency
NCP and NCF white boxes are highly power-efficient. Their typical power consumption without transceivers is 667W and 377W respectively for 28.8T and 19.2T switching capacity. This allows for flexible physical placement. Depending on the data center’s power and thermal capacity, NCPs can be placed with xPU servers in the same rack or with NCFs in networking racks. This flexibility in power and thermal properties has allowed ByteDance to place NCPs and NCFs in optimal configurations within the data center.
Proven solution
Online for two months at the time of this post, the cluster handles a mixture of inference and training traffic from various applications. ByteDance’s existing operational toolkits, designed for non-scheduled fabrics, were easily ported to this cluster. The cluster has demonstrated excellent performance, as expected, and provided a smooth user experience.
And this is just the beginning…
Related content for AI networking architecture
DriveNets AI Networking Solution
Latest Resources on AI Networking: Videos, White Papers, etc
Recent AI Networking blog posts from DriveNets AI networking infrastructure experts
white paper
Utilizing Distributed Disaggregated Chassis (DDC) for Back-End AI Networking Fabric