



|
Getting your Trinity Audio player ready...
|
Below is the distribution of generative AI use cases across industries
Fabric Shift Towards Ethernet for AI clusters
The roots of large-scale computing clusters for complex problem-solving can be traced back to the mid-20th century. However, the utilization of high-performance computing (HPC) for AI-like tasks has taken off in the past decade. Hyperscalers and other HPC cluster builders have embraced specialized hardware and software to optimize clusters for their new requirements.
Nvidia is the main beneficiary from the AI gold rush. Most enterprises are familiar with Nvidia solutions and use its GPUs and connectivity solutions based on InfiniBand. Having said that, enterprises also understand the potential risks associated with vendor lock-in and are advocating for a more diversified vendor ecosystem. As a result, there’s a rising preference for more open and well-established connectivity protocols like Ethernet.
While the forecast is that Ethernet will replace InfiniBand, Ethernet’s main shortcoming currently is related to performance. To close this performance gap, several Ethernet “enhancements” are available including:
- proprietary endpoint-based congestion control mechanisms
- open Ultra Ethernet Consortium (UEC), which is dedicated to delivering an Ethernet-based, open, interoperable, high-performance, full-communications stack architecture to meet the growing network demands of AI and HPC at scale
- scheduled fabric alternatives such as Distributed Disaggregated Chassis (DDC), Cisco’s Disaggregated Scheduled Fabric (DSF) and Arista’s Distributed Etherlink Switch (DES), which provide the highest performance at the scale required for training AI workload.
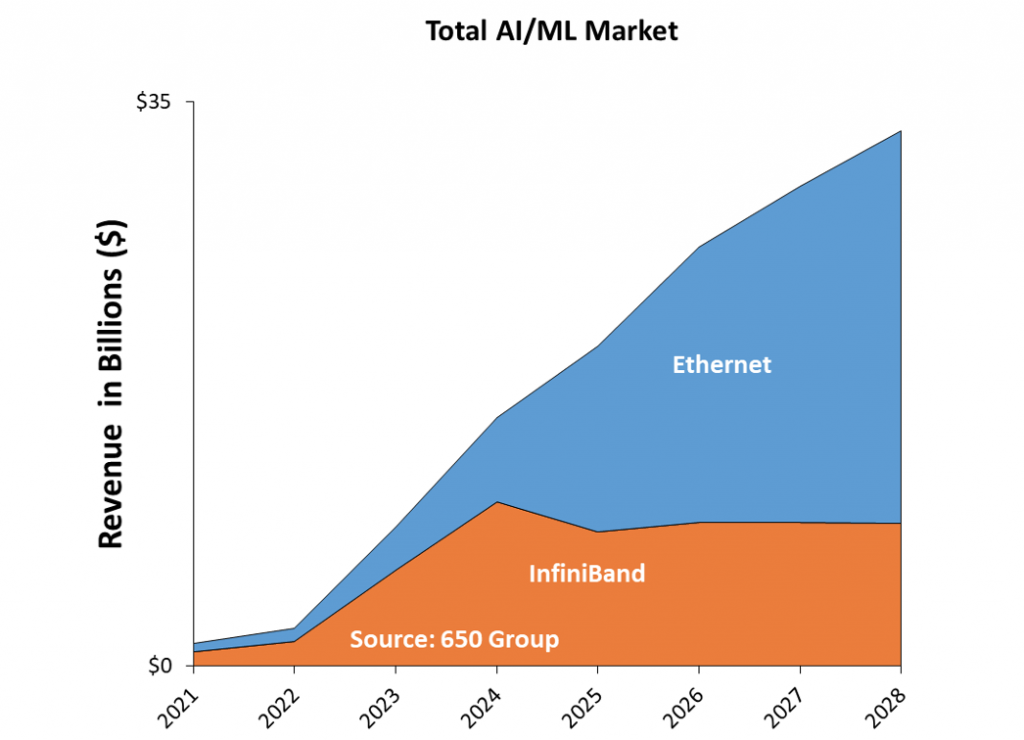
InfiniBand vs Ethernet Forecast
Research firm 650 Group anticipates that Ethernet-based solutions will significantly outperform InfiniBand in the AI/ML (machine learning) market. While InfiniBand holds approximately two-thirds of market value in 2024, the forecast indicates that Ethernet-based solutions will capture over 70% of the market by 2028.
Key enterprise requirements for networking infrastructure
Most recent AI news focuses on hyperscalers (like Microsoft, Google, Meta, and Amazon) building massive AI workload clusters with up to 32K GPUs to train large models like GPT, LaMDA, and DALL-E. This blog post concentrates on enterprises building smaller yet substantial AI workloads ranging from 1K to 8K GPUs. Even at this scale, managing the infrastructure presents numerous complexities in data handling, computing, algorithm optimization, and cluster connectivity.
This section explores the networking challenges and key requirements faced by enterprises building AI workloads, and how DriveNets Network Cloud–AI addresses these needs.
Deliver great performance in large-scale environments like AI workloads
The most crucial requirement when it comes to AI workloads is performance. AI workloads for training demand high-performance, lossless, and predictable connectivity between GPUs to reach the most efficient and optimal job completion time (JCT) targets. As mentioned above, most enterprises are used to working with Nvidia’s InfiniBand solution, despite its inherent difficulties (configuration complexity, vendor lock, cost, etc.), as it can deliver great performance.
DriveNets Network Cloud-AI is a distributed network operating system (NOS) that utilizes a Distributed Disaggregated Chassis (DDC) architecture. This scheduled fabric sprays cells across the entire fabric to ensure perfectly equal load balancing. This, combined with a virtual output queue (VoQ) mechanism and grant-based flow control, allows for a truly lossless environment with non-blocking, congestion-free fabric, just like the backplane of a chassis. Additionally, hardware-based link recovery ensures high performance and reliability, especially in demanding, large-scale environments like AI workloads.
DriveNets has demonstrated up to a 30% improvement in JCT compared to standard Ethernet in production environments across several well-known hyperscaler networks including ByteDance
Minimize the need for AI cluster reconfiguration
Large clusters with thousands of GPUs can be challenging to configure, especially when aiming for optimal performance. Unlike other Ethernet-based solutions, which often require extensive tuning and configuration adjustments (buffer sizes, PFC, ECN, and more), DriveNets Network Cloud-AI offers a flexible and adaptable solution that minimizes the need for reconfiguration. This allows for seamless transitions between workloads and GPU/NIC vendor changes. Once connected, DriveNets Network Cloud-AI delivers a high-performance Ethernet-based fabric connectivity without the burden of complex configurations.
First AI networking scheduled fabric deployed in production
Battle-proven AI networking solutions demonstrate their reliability through ongoing operation in diverse and demanding AI workload environments. Many enterprises tend to use default InfiniBand-based solutions primarily due to these considerations.
DriveNets Network Cloud-AI is the first to deploy a DDC AI scheduled fabric in production at ByteDance, one of the first large-scale Ethernet-based AI backend network deployments in the world. Its operation in production environments at the world’s leading hyperscalers with thousands of GPUs has demonstrated its reliability and performance in real, ultra-large-scale environments.
Complete suite of observability options for AI workloads
Enterprises with significant AI workloads require advance observability and monitoring capabilities to identify and resolve performance issues, ensure high availability, and analyze AI model behavior. This advanced capability should be able to deliver a wide range of observability tools, from low-level options like CLI and SNMP to higher-level capabilities like APIs for seamless integration and automation. Both are necessary because internally developed AI clusters, on one hand, rely on traditional command-line tools for ad hoc problem-solving; on the other hand, limited human resources make simplicity and automation crucial as well.
DriveNets Network Cloud-AI offers a complete suite of observability options. At the lower level, it enables the operation of the entire cluster as one network entity using a single CLI, gRPC, NETCONF/YANG, and more. At the higher level, it leverages DriveNets Network Orchestrator (DNOR) as an end-to-end platform for network monitoring, planning, and optimization through APIs. DNOR’s seamless integration with other management systems allows for full utilization of its capabilities, including automation features such as zero-touch provisioning (ZTP) and seamless software upgrades. This significantly reduces operational costs and efforts.
Enhance the storage network
Storage plays a crucial role in AI workloads as it directly impacts performance. When building a cluster infrastructure, it is essential to ensure perfect alignment of the storage network as well.
When using DriveNets Network Cloud-AI, cluster builders can utilize the capabilities of DDC to enhance the storage network:
- Sandboxed multi-tenancy: The inherent sandboxed multi-tenancy capability of the DriveNets DDC cluster ensures that both storage and compute traffic can run on the same fabric without affecting each other (noisy neighbors). This eliminates the need for special overlay technologies (e.g. VxLAN), which can introduce latency and require complicated configurations. DriveNets allows for both the storage and compute tenants to be natively separated.
- Advanced storage features: The separated environment opens the door to advanced features, such as running storage over remote direct memory access (RDMA). While this is not commonly done in most AI workloads, it can significantly reduce cluster complexity and operational efforts.
Should InfiniBand Still Be the AI Cluster Default for Enterprises?
As previously mentioned, most enterprises are accustomed to using Nvidia solutions, including Nvidia GPUs and InfiniBand connectivity, due to their excellent performance compared to standard Ethernet Clos. However, these solutions can be expensive, require specialized skills, and lead to vendor lock-in.
DriveNets Network Cloud-AI offers enterprises a superior solution. With its scheduled fabric, it can deliver the highest performance without the drawbacks of vendor lock-in, high cost, and complicated operations. Whether prioritizing performance, simplicity, experience, monitoring, or storage, DriveNets Network Cloud-AI is the optimal choice.
Key Takeaways
- AI networking fabric-scheduled Ethernet closes the inherent performance gaps in standard Ethernet solutions
- Performance: DriveNets has demonstrated up to a 30% improvement in JCT compared to standard Ethernet in production environments.
- Simplicity: DriveNets Network Cloud-AI delivers a high-performance Ethernet-based fabric connectivity without the burden of complex configurations.
- Deployment: DriveNets Network Cloud-AI is the first to deploy an AI Networking scheduled-fabric Ethernet in production at ByteDance.
- Observability: DriveNets Network Cloud-AI offers a complete suite of observability options that significantly reduces operational costs and efforts.
- Storage: DriveNets Network Cloud-AI’s cluster builders can utilize the capabilities of AI Networking scheduled-fabric Ethernet to enhance the storage network.
Related content for AI networking architecture
DriveNets AI Networking Solution
Latest Resources on AI Networking: Videos, White Papers, etc
Recent AI Networking blog posts from DriveNets AI networking infrastructure experts
eGuide
AI Cluster Reference Design Guide