



|
Getting your Trinity Audio player ready...
|
That assumption is breaking down. Different AI workloads stress hardware in fundamentally different ways, and as the mix of workloads grows, the cost of forcing all of them onto the same chip grows.
Source: Omar Baldonado (Meta), “AI Data Center Networking: Lessons from Meta’s Evolution,” NANOG 96 keynote.
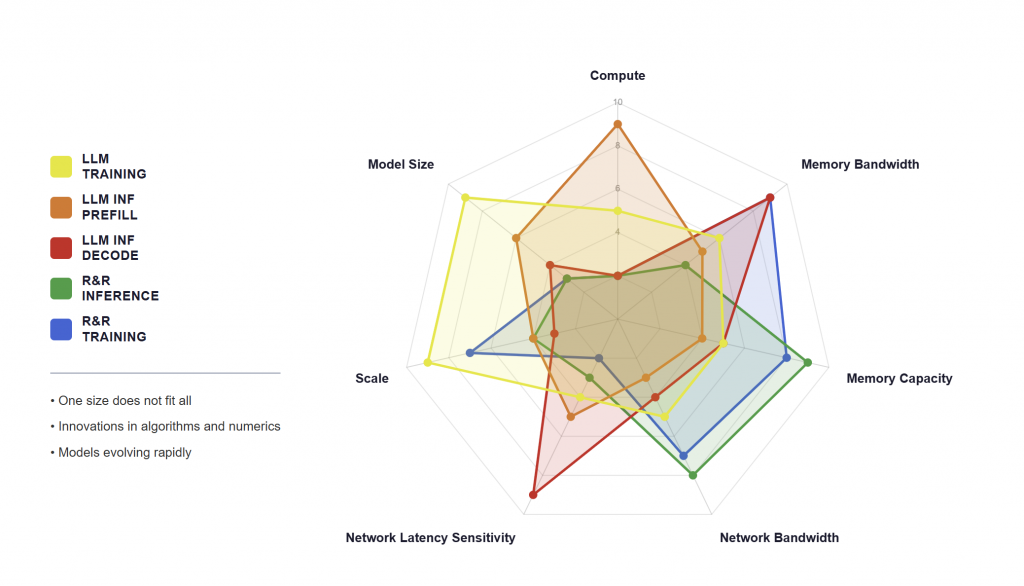
One size does not fit all
Training a large model, running it for users, ranking content, and serving multimodal queries all push on different parts of the hardware – some need raw compute, some need memory bandwidth, some need vast memory capacity, some need more networking, some need all of the above at once. Meta’s own infrastructure team has put it in exactly those terms: their workloads occupy very different points on the same set of axes, and there is no single chip that sits at the top of all of them. The radar chart above makes that visible – five workload types, seven resource axes, five different shapes.
Inference is where this matters most
The training era of AI was relatively forgiving: training is one big synchronous job, runs on identical hardware, and happens once per model. Inference is the opposite. It runs continuously, on every request, for the entire lifetime of the model – and it now accounts for more than 90% of what large-scale AI actually costs to operate. As models move from chatbots to agents, copilots, and always-on assistants, the share of compute spent on inference only grows. Optimizing inference hardware is no longer a nice-to-have; it is the main lever on AI economics.
And inference itself contains a built-in contradiction. Every request goes through two stages with opposite hardware preferences. The first stage, prefill, reads the entire prompt at once – a heavy lift of raw arithmetic that wants as much compute horsepower as possible. The second stage, decode, produces the answer one word at a time, constantly shuttling large amounts of data in and out of memory; the bottleneck is no longer compute but how fast the GPU can read its own memory. On the same chip running the same model, prefill can keep nearly all the compute units busy while the decode that follows leaves most of them idle. A GPU sized for one stage is the wrong size for the other. And the mismatch goes deeper than the two stages: even within a single stage, the Attention and feed-forward (FFN) layers lean on different resources – Attention is dominated by memory movement around the growing key-value cache, while the FFN is dense arithmetic – so the ideal hardware shifts layer by layer, not just stage by stage. Prefill-versus-decode is the most familiar split, but it is only the first cut; there are more ways to optimize and disaggregate a model than this, and the more finely you look, the more of them appear.
AGI will make the picture more diverse, not less
Today’s inference mix is already two workloads in one. Tomorrow’s – long-horizon reasoning, multi-agent systems, persistent memory, real-time multimodal generation, tool-using copilots running for hours instead of seconds – adds workload shapes that don’t yet have settled hardware profiles. The space of things inference has to do is expanding, and with it the gap between what a single GPU is good at and what the workload actually needs. The case for matching hardware to workload only gets stronger.
What is Heterogeneous AI?
Heterogeneous AI means matching each stage of inference to the kind of hardware it actually needs, rather than picking one GPU and using it for everything. In its most common form, prefill runs on one set of GPUs and decode runs on another. The intermediate state — what the prefill stage worked out about the prompt — is handed off between them over a high-speed network connection.
The hardware industry is moving in this direction in unusually visible ways. At GTC 2026, NVIDIA unveiled its Vera Rubin platform with two co-designed accelerators sitting side by side: Rubin GPUs built around high-bandwidth memory for the compute-heavy prefill stage, and Groq 3 LPX racks built around large pools of on-chip SRAM for ultra-low-latency decode. NVIDIA is the dominant GPU vendor, and it chose to pair its own silicon with a second, fundamentally different chip in the same rack rather than push one design to cover both jobs.
In a similar manner, Google has announced that its next-generation TPUv8 will come in two variants: TPUv8t for training and TPUv8i for inference. Independent measurements back up the case: the DistServe paper (USENIX OSDI 2024) shows that splitting prefill and decode across separate GPU pools serves up to 7.4x more requests within the same latency budget than co-located serving, or holds the same throughput against 12.6x tighter SLOs. That is about as strong an industry signal as the prefill-versus-decode mismatch is going to get.
Research groups have gone further, showing that even mixed pools of older and newer GPUs, or chips from different vendors, can be combined to serve inference economically. A useful side effect is more flexibility on the procurement side: once the system can place each stage independently, an organization is no longer locked into a single chip or vendor for its entire fleet.
The shift is already visible in the software that companies use to serve models. The major open-source serving frameworks now treat split prefill and decode as a standard deployment option, not an experimental one.
Inference Technical Challenges
Splitting inference across different kinds of hardware is easy to describe and hard to do well. Four problems dominate.
- Abstraction
Different GPUs, especially from different vendors, do not behave the same way under the hood. They organize memory differently, distribute work differently, and ship with different software stacks. A system that runs inference across a mixed fleet needs a common layer that hides those differences from the rest of the stack. Without it, every new chip is a custom integration project. - Orchestration
Prefill and decode interfere with each other when they share hardware: a prefill step is expensive enough that it slows down any decode work running alongside it. Once the two stages are split across different pools, a new question takes its place – how many prefill machines does the fleet need for every decode machine? The right ratio depends on the mix of requests coming in, and that mix shifts hour to hour and even minute to minute. The orchestration layer has to keep up. - Networking
Splitting the two stages means moving data – sometimes a lot of it – from the prefill machine to the decode machine, on every single request, fast enough that the user does not notice the handoff. That puts the network between GPUs on the critical path. A standard datacenter network is not fast enough for this; specialized high-speed interconnects are required, one which is optimized throughout the full stack, including NIC and CCL layers. Networking becomes a first-class part of the architecture rather than something you order last. - Uneven traffic:
Real-world inference traffic is messy. Long analytical questions, quick conversational replies, and multi-step agent runs all behave very differently. A setup that pays off for a long, complex request can actively hurt performance on a short, simple one – published industry numbers put that penalty in the 20–30% range when the split is applied to workloads that do not need it. The system has to decide, for each individual request, whether splitting is the right move.
Heterogeneous AI: The Future of High-Performance, Efficient Infrastructure
Heterogeneous AI is not a free win and not the right answer for every situation. But the direction is clear. Inference is two workloads with opposite hardware needs, the chip industry is shipping more specialized silicon to match, and the software that runs models is catching up. The interesting question for the next few years is no longer whether to split inference across different kinds of hardware, but when, how aggressively, how efficiently and across which mix of chips.
Further reading
- Towards Data Science – “Prefill Is Compute-Bound. Decode Is Memory-Bound. Why Your GPU Shouldn’t Do Both”
- Data Gravity – “The Inference Unbundling: Why Prefill and Decode Are Splitting the GPU”
- BentoML LLM Inference Handbook – Prefill-Decode Disaggregation
- HexGen-2 –Disaggregated Generative Inference of LLMs in Heterogeneous Environment (arXiv 2502.07903)
- Cronus – Efficient LLM Inference on Heterogeneous GPU Clusters via Partially Disaggregated Prefill (arXiv 2509.17357)
- Disaggregated Prefill and Decoding Inference System for LLM Serving on Multi-Vendor GPUs (arXiv 2509.17542)
- NVIDIA – “NVIDIA Groq 3 LPX: Inference Accelerator for Agentic AI” (Vera Rubin + Groq LPU co-designed platform)
- Google Cloud – “Our eighth generation TPUs: two chips for the agentic era” (TPUv8t for training, TPUv8i for inference)
- Morph – “LLM Inference: Prefill, Decode, KV Cache & Cost Guide (2026)”
Key takeaways
- One-size-fits-all hardware is breaking down
Different AI workloads stress different resources (compute, memory bandwidth, memory capacity, networking), and no single GPU sits at the top of all of them – so forcing every workload onto one flagship chip is increasingly costly. - Inference, not training, now drives AI economics
Inference runs continuously on every request and accounts for more than 90% of large-scale AI operating cost – and its share grows as AI moves toward agents, copilots, and always-on assistants. - Inference has a built-in hardware contradiction
Prefill (compute-heavy) and decode (memory-bandwidth-bound) want opposite chips, and the mismatch goes even deeper — Attention vs. FFN layers favor different resources. A GPU sized for one stage is wrong for the other. - Heterogeneous AI is the emerging answer
Matching each stage to purpose-built hardware delivers big gains (DistServe: up to 7.4x more requests at the same latency), and the industry is already shipping for it (NVIDIA Vera Rubin, Google TPUv8t/v8i). The challenge is execution: abstraction across chips, orchestration, high-speed networking, and deciding per-request when splitting actually helps..
Frequently Asked Questions
Why does inference matter more than training for AI hardware costs?
Inference accounts for more than 90% of what large-scale AI costs to operate. Unlike training, which runs once per model, inference runs continuously on every request for the model’s entire lifetime. As AI shifts toward agents, copilots, and always-on assistants, inference’s share of compute — and its impact on overall economics — keeps growing.
What is Heterogeneous AI?
Heterogeneous AI matches each stage of inference to the hardware it actually needs, rather than using one GPU for everything. Typically, the compute-heavy prefill stage runs on one set of GPUs while the memory-intensive decode stage runs on another, with the intermediate state handed off between them over a high-speed network connection.
How much does splitting prefill and decode improve inference performance?
Splitting prefill and decode across separate GPU pools serves up to 7.4x more requests within the same latency budget, according to the DistServe paper (USENIX OSDI 2024), or sustains equal throughput against 12.6x tighter latency targets. Applying the split to simple requests that don’t need it, however, can cost 20–30% in performance..
Related content for AI networking infrastructure
DriveNets AI Networking Solution
Latest Resources on AI Networking: Videos, White Papers, etc
White Paper
Scaling AI Clusters Across Multi-Site Deployments