From the outset, DriveNets sought to address the daunting task of developing a fully distributed network operating system that would allow carrier service providers and enterprises to leverage the new wave of open networking architectures and merchant silicon – without any degradation to the level of service their customers expect.
Through 4-5 iterations in our development process, we soon realized that the biggest challenge for Drivenets’ Network Operating System DNOS, first and foremost, was to build a firm foundation on which networking services could be implemented. The most challenging tasks were virtualizing the compute and networking resources, as well as distributing microservices and their respective High Availability mechanisms.
Like in any distributed and non-distributed system, when scale comes into play, it amplifies the probability of error, exposing any design weakness.
Combining strong efforts in system, white box and software design, we eventually decided to make a clear set of simple goals that would be used to evaluate any design criteria for DNOS:
Built for any scale – the same operating system that runs on a 4Tbps standalone box can scale to a network entity of hundreds of Tbps.
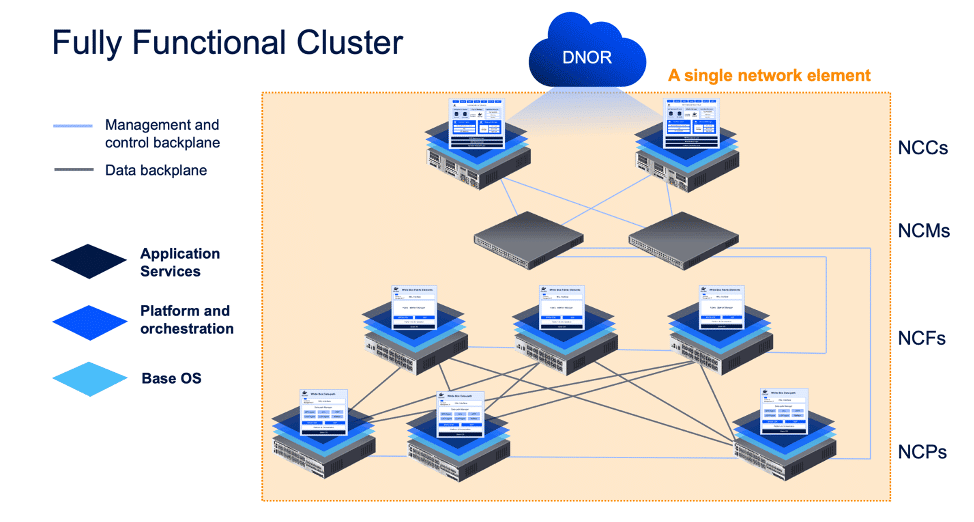
Simple to operate – once provisioned, the cluster, no matter how large, acts as a single network entity, like the familiar chassis-based router.
Single software for all cluster sizes – the same containers are deployed to all white boxes, whether in a standalone or cluster formation.
Full system architecture – to ensure that the network is not a projection of the router, rather, the router is a projection of the network.
DNOS is More than a Network Operating System
Doing that, we proved to ourselves and to our customers that DriveNets Network Operating System (DNOS) is much more than a network operating system. It’s a virtualization layer running over white boxes and servers. Furthermore, we understood that while looking at existing NOS designs could shed light on specific use cases, they did not fit the exact problem domain we were exploring. Therefore, the design needed to be built using architectures that were more more similar to the way webscalers built cloud infrastructure, than to how traditional routing or switching OSs (e.g. IOS, Junos, etc) built them.
The design guidelines we put forward:
Natively distributed NOS: Contrary to monolithic software, we do not assume any specific location for any management or networking function, every element is encapsulated as a container which gives us the flexibility to orchestrate it.
Extensive use of containers: To ease development, deployment, and upgrade – DNOS containers are services which are built, tested and deployed as units
Optimized resource utilization: Every compute resource is utilized not just on the servers, so that services like LACP, BFD, Flow monitoring, etc can be handled locally on the NCP without overloading the controller (i.e. the NCC server). This allows for linear growth whenever a new NCP is added.
User space code: Since virtual network functions and any other high performance packet processing software cannot scale within the kernel, we built them as a user space code – providing us a better way to control their execution paradigm (for example using CPU pinning), as well as for upgrading, debugging and maintaining them.
The use of microservices has proved itself to be the most important design choice, enabling us to use the same software form factor on different physical form factors.
We use Docker containers in every part of the software:
In the infrastructure layer: auto-discovery of the docker containers and mechanisms for connecting to the right container at the right time (e.g. during a switchover, graceful restart, BGP NSR, etc.)
In the management plane: despite the numerous microservices, users experience a single network element (e.g. single SSH session to a single single CLI, just like the monolithic router)
In the control plane: the routing protocols are containerized and can run either on a server or on the x86 chip inside the white box using the same software
In the data plane: Data-path services are containerized and exposes software and/or hardware based functions (e.g. ACLs, Routes FIB, Flow-monitoring services, performance and fault measurements)
Creating Large Scale Clusters
The challenges that we faced, far beyond networking, were in creating large scale clusters. The distributed nature of the cluster makes this task difficult, as they span a multitude of compute and networking elements and include a large number of software services:
Multiplexing management and control traffic (e.g. BGP, IS-IS, etc.) – from all the line cards at scale together with internal needs like cluster management, traces, counters, etc
Layered and distributed high availability – so that decisions can be taken locally even when they have a global effect
Large distributed transaction – the ability to commit user defined configuration that provision all line cards without being service affecting
Timing synchronization – the ability to synchronize all the white boxes to the same time base for service and other needs (logs, traces, certificates)
Allocation of module IDs – while the chassis uses slots to identify modules, for the disaggregated system we had to reinvent the mechanism
Handling distributed logs and traces – the ability to debug the system by easily tracing a system wide event as though looking at a virtual log file aggregating log entries from many elements