



|
Getting your Trinity Audio player ready...
|
Failures in a large-scale AI cluster are common. As described by Mark Russinovich, CTO of Microsoft Azure, such failures are caused by various reasons including link flap, GPU health check failures, kernel panics and so on.
The Distributed Disaggregated Chassis (DDC) architecture, as defined by the Open Compute Project, offers significant benefits when it comes to different kinds of failures.
Application-driven failure
If failures derive from the application level – namely if it’s a scheduler issue or a rogue job issue that makes one (or more) of the GPUs generate more traffic than the others – this leads to an uneven distribution of traffic. The DDC system is agnostic to it, as the traffic is evenly sprayed across the fabric. As a result, no elephant flows, incast congestion or other phenomena can cause packet drops.
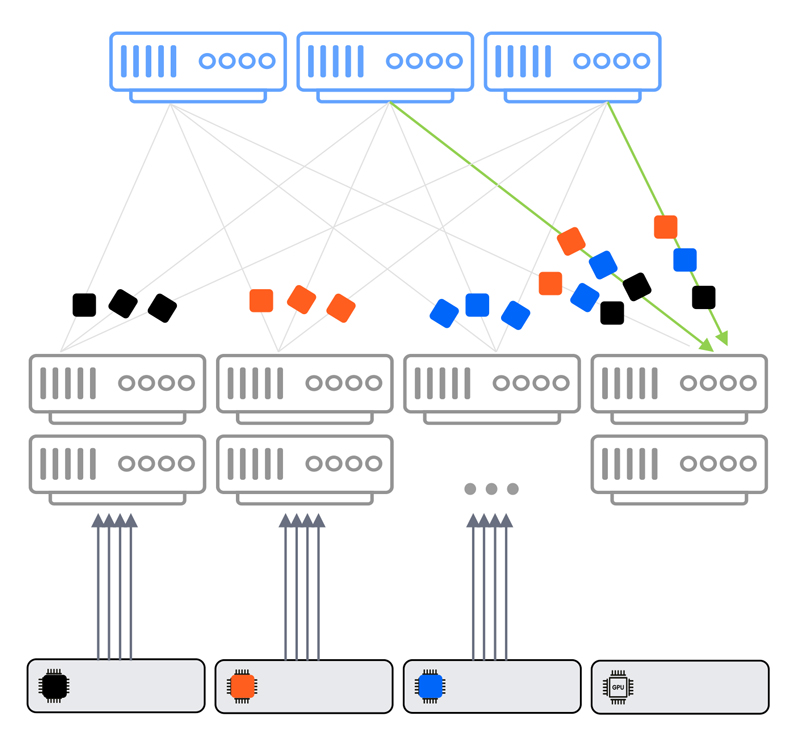
DDC incast congestion scenario
This is different than a classic Ethernet Clos architecture in which incast congestion can cause a job failure due to severe packet loss.
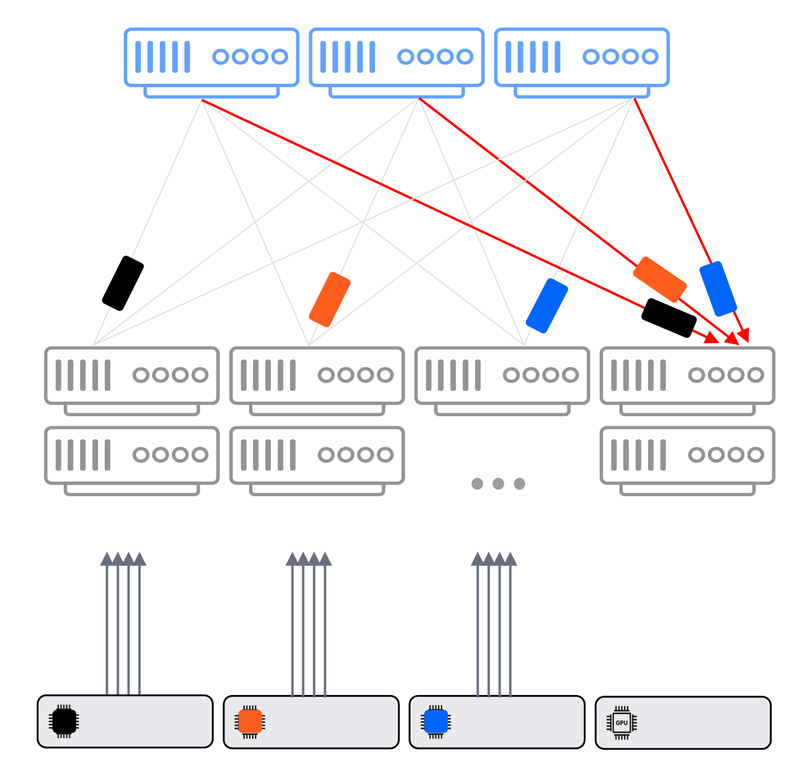
Ethernet Clos incast congestion scenario
Top-of-rack network failure
In cases when a top-of-rack (ToR) switch fails, and assuming the GPU servers in this rack do not have a redundant connectivity scheme, the entire rack is disabled. It is, then, up to the job scheduler to redistribute the compute resources. This means it’s only a matter of how fast such a failure is identified and how quickly this knowledge is propagated throughout the networking fabric, which is similar to the handling of a fabric failure.
Fabric link network failure
A recovery from a fabric failure event (e.g., a link failure between a leaf switch and a spine switch) is dependent on two main parameters:
- How fast can the networking fabric identify the failure?
- How fast can the networking fabric converge to an architecture that accommodates this failure?
DDC shows significant benefits for both parameters.
- Failure detection is done on the hardware level and is not dependent on a software-based keep-alive message. This means nanoseconds instead of seconds until failure is detected.
- Once failure is detected, DDC, which is a single Ethernet entity, is immediately updated via the Network Cloud Fabric (NCF) and local agent on the Network Cloud Packet Forwarder (NCP). The centralized DriveNets Network Operating System (DNOS) controller updates the FIB entries on all NCPs in the cluster. Again – convergence time is measured in nanoseconds.
For Ethernet Clos, on the other hand, an internal protocol (xSTP or other) is required for the propagation, and each leaf, which is a separate Ethernet entity, recalculates the topology and updates its own FIB. This process takes seconds.
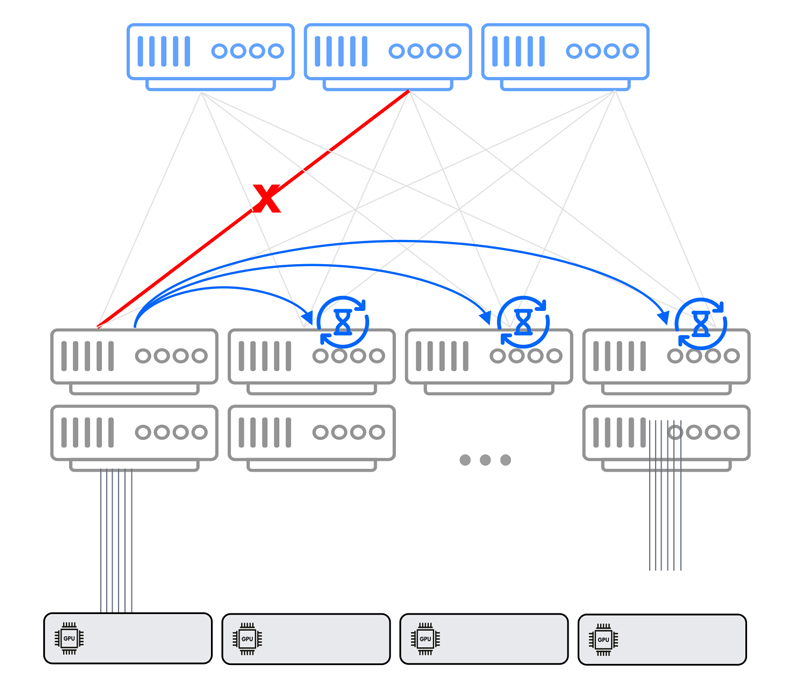
Network failure recovery – Ethernet Clos
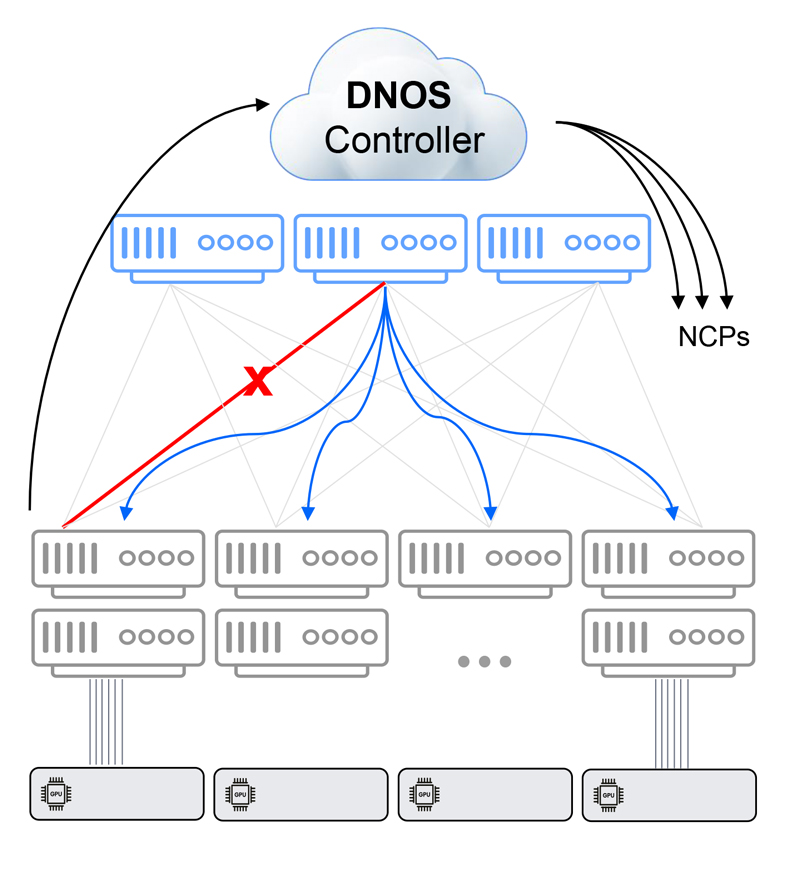
Network failure recovery – DDC
This difference is dramatic when it comes to job performance. In some cases, it marks the difference between a slightly delayed job and a job that needs to restart (back from the last checkpoint or from the start altogether).
Network recovery failure with a DDC Ethernet solution
When it comes to an AI networking fabric, its failure recovery dramatically influences AI cluster performance in terms of JCT.
For AI backend networking fabric, DDC exhibits faster failure identification and convergence, and is agnostic to traffic pattern anomalies. As a result, DDC is the top-performing Ethernet solution and AI networking solution.
Download White Paper
Utilizing Distributed Disaggregated Chassis (DDC) for Back-End AI Networking Fabric